网络爬虫,在数据驱动的时代中,已经崭露头角,成为了获取、处理和分析数据的不可或缺的利器。但是,随着目标网站不断加强反爬策略,仅仅掌握基础的爬虫方法和技巧似乎已经不能满足日益增长的需求。在这场网络版的“猫鼠游戏”中,如何确保你的“鼠”始终领先一步呢?一个有效的答案便是:通过巧妙和高效地使用代理。为此,我们将为你展示一系列关于代理的高效使用技巧,结合穿云API的强大功能,帮助你的网络爬虫真正实现“无所不能”。
1:动态IP轮换
无论你如何努力,使用单一IP长时间爬取数据总是会触发目标网站的警报。动态住宅代理确保了每次请求都使用一个新的IP地址,大大减少了被封锁的风险。

2:绕过高级防护
许多网站使用如Cloudflare 5秒盾、人机验证、WAF和CC防护等高级安全机制。其拥有强大的绕过能力,能够突破这些防护,确保爬虫的正常工作。

3:地理定位抓取
有些数据可能因地域而异。其允许你选择特定的地理位置,模拟当地用户进行数据爬取,确保数据的完整性和准确性。
4:定制的采集流程
不同的任务需要不同的数据采集策略。穿云API的高度可塑性,让你可以根据任务需求定制数据采集流程,无论是简单的网页抓取,还是复杂的登录模拟和跨平台操作。
5:稳定的速度和响应
当你进行大规模的数据采集时,稳定的响应速度和成功率显得尤为重要。提供稳定、快速的代理服务,让你的爬虫任务更加高效。
6:用户友好的界面和支持
无论是初学者还是经验丰富的开发者,简单易用的界面和丰富的文档支持,确保你可以快速上手,并在遇到问题时获得及时的帮助。
7:自动生成代码功能:对于不熟悉编程的用户,穿云API提供了自动生成代码的功能,只需几次点击,即可生成针对特定任务的爬虫代码,大大节省了开发时间和资源。
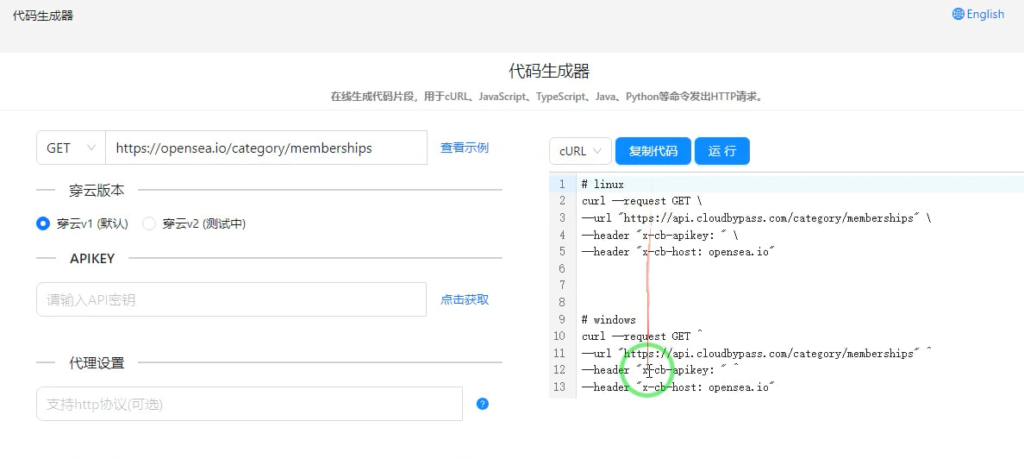
总结:对于网络爬虫,代理不再是一个可有可无的选项,而是一个关键的工具,可以大大提高数据采集的效率和成功率。结合穿云API等先进的代理服务,你可以克服各种网络障碍,让你的爬虫真正地“无所不能”。




