
作为一名从事新闻和小说业务的内容创作者,我深知数据的重要性。在这个信息化时代,快速获取有价值的数据已经成为行业竞争力的重要标志。尤其是我在撰写新闻报道和小说创作过程中,时常需要抓取互联网上的各种数据,包括文章、新闻头条、小说情节以及用户评论等。然而,随着越来越多的网站开始使用Cloudflare进行反爬虫保护,抓取数据的难度急剧增加,尤其是Cloudflare的五秒盾和Turnstile CAPTCHA验证,给我的工作带来了巨大的困扰。
在一次次被阻挡的过程中,我几乎丧失了信心。但幸运的是,我发现了穿云API这个强大的工具,它帮助我轻松绕过Cloudflare的防护措施,实现高效的数据采集。今天,我想分享我的亲身经历,讲述穿云API如何在突破Cloudflare的反爬机制上,成为我新闻和小说数据采集的得力助手。
一、Cloudflare反爬的严峻挑战
作为一个新闻工作者和小说创作者,我每天都需要获取大量的信息和数据。Cloudflare作为全球领先的网络安全平台,以其强大的反爬虫功能广泛应用于各大网站。它的反爬虫机制包括五秒盾和Turnstile CAPTCHA验证,旨在识别并阻止爬虫程序和恶意攻击。
五秒盾是Cloudflare的一项核心反爬功能。每当我尝试访问一个启用了Cloudflare的目标网站时,我会看到一个5秒钟的延时,等待期间还会弹出各种“验证我不是机器人”的提示,甚至可能要求我选择图片中的特定物体,或者确认我能正确辨识一些模糊的字母和数字。
而Turnstile CAPTCHA则更具挑战性。这是一种图形验证码,它要求用户通过点击或拖动特定区域来验证自己的身份。如果你是一个爬虫程序,它几乎不可能通过这种验证,因为它模仿了人类的行为和思考过程。对于爬虫而言,突破这种验证码简直是一项艰巨的任务。
作为一个新闻采集员和小说创作者,每次遇到这些防护措施时,我都深感沮丧和无奈。这些阻碍让我无法高效地抓取到需要的数据,进而影响到我对新闻事件的报道和小说的创作。
二、穿云API:突破Cloudflare的得力助手
就在我陷入困境之时,我偶然接触到了穿云API,这款工具不仅能够轻松绕过Cloudflare的反爬机制,还能帮助我高效采集数据。穿云API具有强大的功能,尤其是在绕过Cloudflare的五秒盾和Turnstile CAPTCHA验证方面,给我带来了巨大的帮助。
1. 突破五秒盾和WAF防护
穿云API内置了全球高速S5动态IP代理池,这些IP池中的代理IP覆盖了世界各地,可以通过随机切换IP来绕过Cloudflare的IP检测。每次发送请求时,穿云API都会自动选择一个新的IP地址,避免了Cloudflare对单一IP的封锁和追踪。因此,我不再需要担心每次被封IP,能够持续稳定地访问目标网站。
更重要的是,穿云API能够通过智能代理技术模拟正常用户的访问行为,从而绕过Cloudflare的五秒盾和WAF防护。这使得我能够顺利地获取需要的数据,而不会被系统强行拦截或要求输入验证码。
2. 突破Turnstile CAPTCHA验证
对于Turnstile CAPTCHA验证,穿云API的另一项强大功能便是自动化的反CAPTCHA技术。穿云API模拟了真实用户的浏览器环境,能够自动识别并处理各种类型的验证码。通过结合浏览器指纹技术,穿云API能够让爬虫的行为看起来像是一个正常用户的操作,避免触发Cloudflare的验证码机制。
3. 高效的HTTP API接口
穿云API提供了一个简洁易用的HTTP API接口,支持多种编程语言调用。这个接口可以帮助我快速集成代理功能,自动切换IP,设置请求头,以及模拟浏览器行为等。以下是穿云API常见的一些请求参数和使用示例:
- 接口地址:
https://api.chuangyunproxy.com - 请求参数:
ip_type: 代理IP类型(动态/静态)ip_count: 代理IP数量referer: 请求来源user_agent: 浏览器User-Agentheadless: 是否启用无头模式(模拟正常浏览器行为)
穿云API的这些参数设置,使得我可以在数据采集过程中,模拟各种不同的浏览器指纹特征,进一步提高成功率。通过设置Referer、浏览器UA、Headless状态等参数,穿云API确保了每次请求看起来都像一个真实用户在访问,避免了Cloudflare的反爬虫系统对我的拦截。
4. 无缝的IP代理池
穿云API提供的全球高速S5动态IP代理池,覆盖了超过200个国家和地区。这些代理IP具有高匿名性,能够有效规避IP封锁。每次通过穿云API发出的请求,都会选择一个新的IP,确保我的数据抓取工作不会因为单一IP被封而中断。此外,代理池中的IP池是动态更新的,提供持续稳定的IP资源,确保我的抓取任务能够顺利进行。
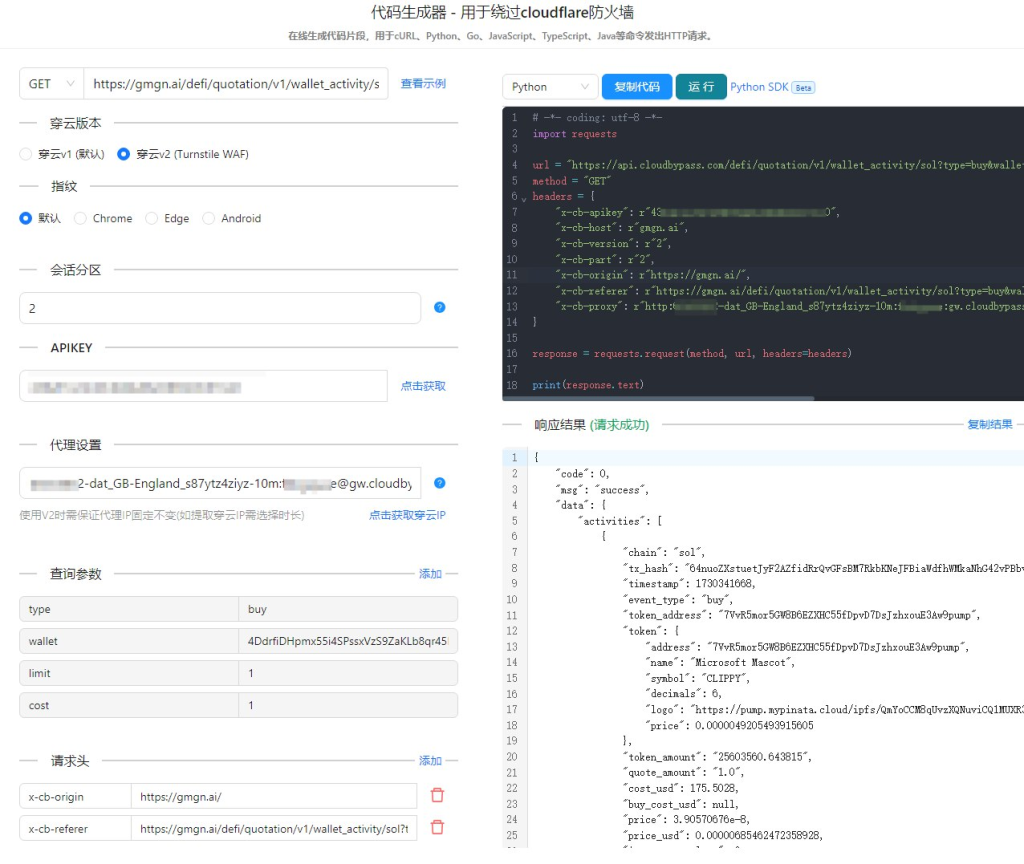
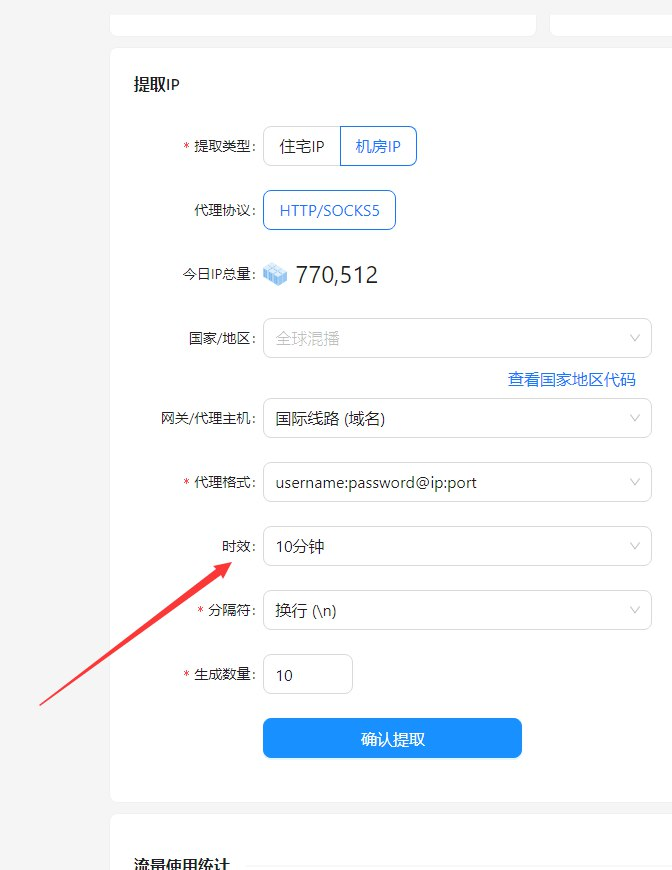
三、实际应用:无阻碍的数据采集
作为一名新闻采集员,我需要定期抓取新闻网站上的最新报道和用户评论。而对于小说创作者来说,抓取网站上的流行小说、用户评分和读者反馈也是创作灵感的重要来源。然而,很多新闻网站和小说平台都启用了Cloudflare的反爬虫保护,这对我来说曾是巨大的障碍。
自从我使用了穿云API后,这些问题迎刃而解。通过穿云API,我能够轻松绕过Cloudflare的五秒盾和CAPTCHA验证,无论是新闻网站上的实时资讯,还是小说平台上的用户反馈,我都能在最短的时间内抓取到需要的数据。数据抓取变得更加高效,创作灵感也源源不断地涌现出来。
在一次新闻报道的抓取过程中,我使用穿云API绕过了Cloudflare的多重防护,成功抓取了大量的相关新闻和用户评论。与此同时,我还能够获取到实时更新的小说章节和读者评分,这对于我创作新的小说情节和新闻分析提供了极大的帮助。
四、突破障碍,数据采集更加轻松
对于从事新闻和小说创作的我来说,数据采集的效率直接影响到我的工作进度和创作灵感。而Cloudflare的反爬虫保护曾经是我最大的障碍。然而,借助穿云API,我不仅成功绕过了Cloudflare的五秒盾和Turnstile CAPTCHA验证,还能够高效地采集到各种数据。
穿云API不仅提供了强大的IP代理池和反爬虫技术,还通过简便的HTTP API接口,让我能够快速集成和使用。这款工具的出现,改变了我在数据采集中的工作方式,也让我在新闻报道和小说创作中,始终保持着领先的优势。




