作为一名数据采集工作者,我深知数据对于企业决策的重要性。然而,随着网站对数据保护意识的增强,越来越多的网站采用了Cloudflare等强大的反爬虫机制,这无疑给我们的工作带来了巨大的挑战。特别是Cloudflare的5秒盾、WAF防护和Turnstile CAPTCHA验证,常常让我感到束手无策,仿佛撞上了一堵坚不可摧的墙。
绝望中的曙光
记得有一次,我需要从一个大型电商平台采集大量商品数据,用于分析竞争对手的定价策略。然而,这个平台的防护非常严密,我尝试了各种方法,包括更换IP、使用代理、修改User-Agent等,都无法绕过Cloudflare的重重关卡。每当看到那些令人垂涎的数据就在眼前,却无法触及,我的内心充满了挫败感。
就在我几乎要放弃的时候,我偶然间发现了穿云API这个工具。一开始,我对它的效果持怀疑态度,毕竟市面上类似的工具层出不穷,但抱着试一试的心态,我决定一探究竟。
穿云API:我的数据采集利器
经过一番研究,我发现穿云API是一款专为突破反爬虫机制而设计的工具。它提供了HTTP API和一站式全球高速S5动态IP代理/爬虫IP池,能够轻松绕过Cloudflare的5秒盾、WAF防护和Turnstile CAPTCHA验证。更重要的是,穿云API支持自定义Referer、浏览器UA和headless状态等各浏览器指纹设备特征,这使得我的请求看起来更加真实,不易被识别为机器人。
亲身体验:突破Cloudflare防线
我迫不及待地将穿云API集成到我的爬虫程序中。首先,我注册了穿云API的账号,并获取了API密钥。然后,我按照官方文档提供的示例,编写了一个简单的Python脚本,通过HTTP API向目标网站发送请求。
令我惊喜的是,穿云API几乎完美地绕过了Cloudflare的所有防护。我能够轻松地访问目标网站,并获取到所需的数据。那种感觉就像是一下子打开了新世界的大门,我仿佛又找回了对数据采集工作的热情。
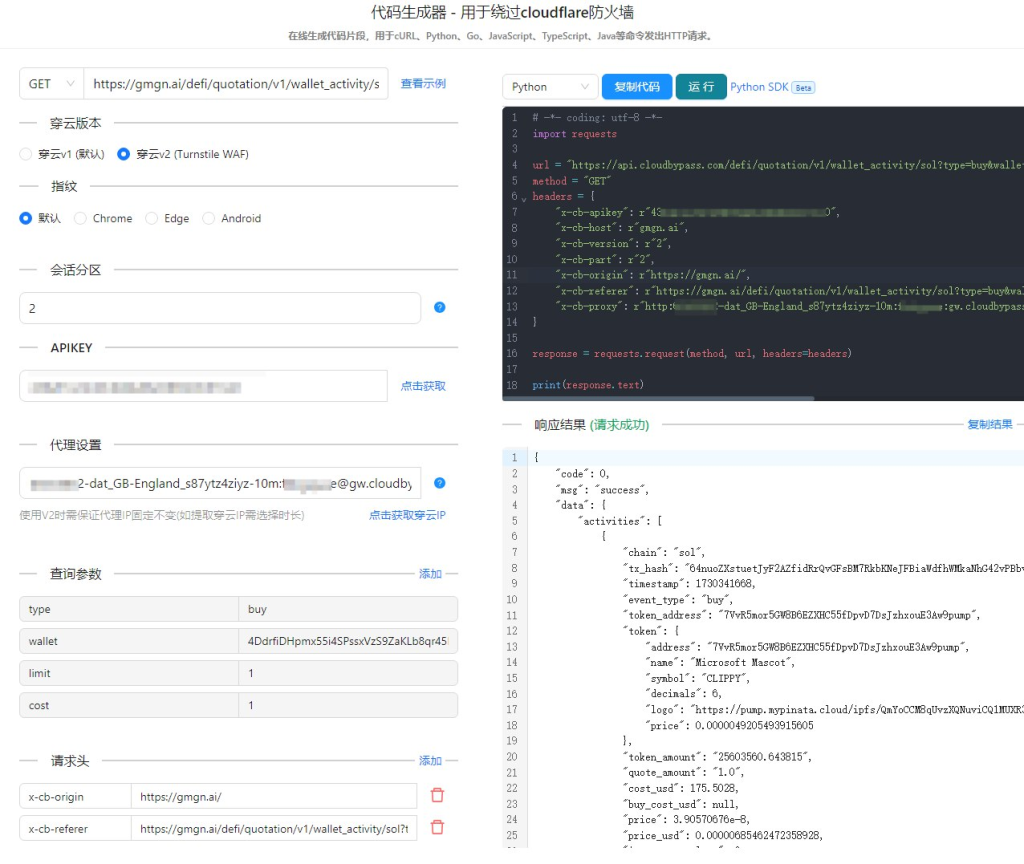
接口地址、请求参数和返回处理
穿云API的接口地址、请求参数和返回处理都非常简单易懂。官方文档提供了详细的示例代码,即使是没有编程基础的人也能很快上手。
- 接口地址: 穿云API提供了一个统一的HTTP接口,通过这个接口,我们可以发送各种类型的请求。
- 请求参数: 请求参数包括目标URL、请求方法、请求头等。我们可以通过设置这些参数来模拟真实的浏览器行为。
- 返回处理: 穿云API会将目标网站的响应返回给客户端。我们可以对返回的数据进行解析,提取出我们需要的信息。
设置Referer、浏览器UA和headless状态
为了进一步提高请求的真实性,穿云API还支持设置Referer、浏览器UA和headless状态。
- Referer: Referer字段可以告诉服务器,当前请求是从哪个页面跳转过来的。通过设置合理的Referer,我们可以模拟用户从搜索引擎或其他网站跳转到目标网站的行为。
- 浏览器UA: User-Agent字段表示客户端浏览器的类型、版本等信息。通过设置不同的UA,我们可以模拟不同设备和浏览器的访问行为。
- headless状态: headless状态是指在后台运行浏览器,不显示浏览器界面。通过设置headless状态,我们可以提高爬虫的效率。
自从使用了穿云API,我的数据采集工作变得更加高效和便捷。再也不用担心被Cloudflare的各种验证机制拦在门外,我可以尽情地探索数据的世界。这种感觉就像是一个探险家,不断地发现新的宝藏。
穿云API无疑是一款非常强大的工具,它帮助我突破了Cloudflare的重重防线,让我能够更加轻松地获取到所需的数据。如果你也从事数据采集工作,并且经常遇到Cloudflare的阻碍,那么我强烈建议你尝试一下穿云API。
温馨提示: 在使用穿云API的过程中,请务必遵守目标网站的使用条款,避免对网站造成过大的负载。同时,也要注意保护自己的隐私信息,不要泄露个人身份信息。