
Cloudflare作为一款强大的网站安全服务,为众多网站提供了坚实的防护。这使得传统的爬虫在获取数据时面临了巨大的挑战。然而,随着技术的不断发展,分布式爬虫系统为我们提供了一种更有效、更灵活的解决方案。本文将深入探讨如何利用分布式爬虫系统绕过Cloudflare的重重防护,并提高数据抓取的速度。
分布式爬虫系统的优势
分布式爬虫系统通过将爬取任务分发到多个节点上并行执行,大大提高了爬取效率。想象一下,将一个大型的图书馆分成多个小房间,每个房间由一位图书管理员负责查找书籍,这样就能比单个管理员更快地找到所有需要的书籍。此外,分布式系统还具有良好的容错性、扩展性,以及负载均衡的能力,能够适应各种复杂的爬取场景。
绕过Cloudflare的策略
绕过Cloudflare的防护需要综合运用多种技术手段。首先,我们可以通过模拟真实用户行为来迷惑Cloudflare。这包括设置合理的User-Agent、Referer、Cookies等请求头,以及模拟用户在页面上的点击、滑动等操作。其次,IP代理池也是必不可少的工具。通过不断更换IP地址,可以有效地绕过Cloudflare的IP封锁。此外,对于一些复杂的验证码,我们可以尝试使用OCR技术或机器学习模型进行识别。
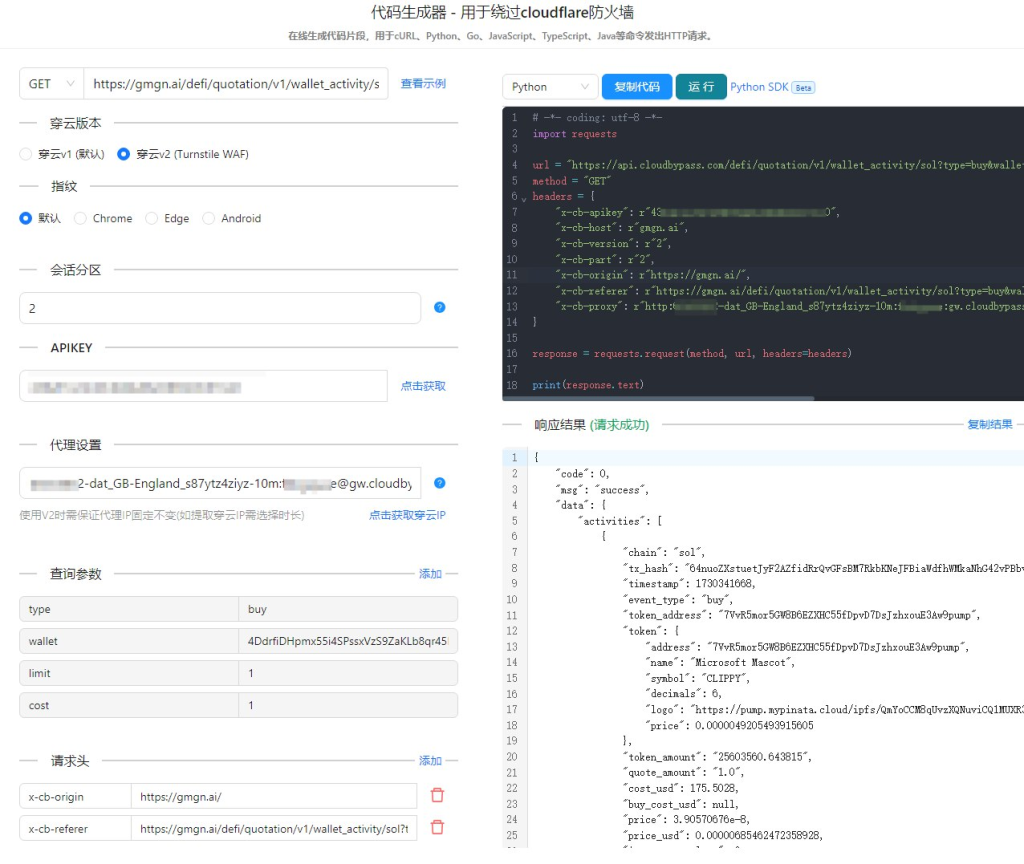
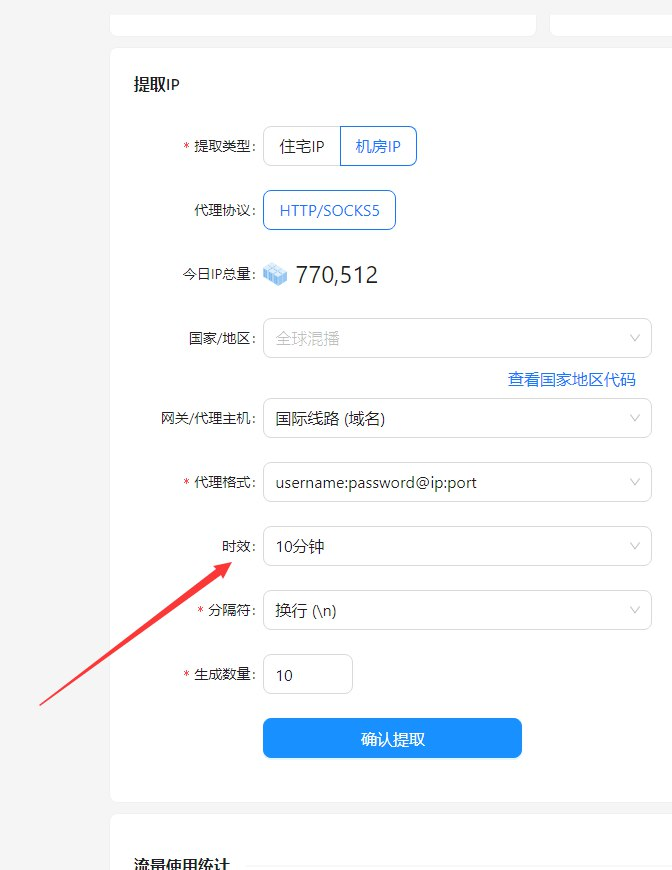
穿云API的引入
在绕过Cloudflare的过程中,我们常常会遇到验证码、IP封禁等问题。穿云API作为一款专业的反反爬虫服务,可以为我们提供高质量的代理IP、智能验证码识别、以及其他反反爬虫工具。通过使用穿云API,我们可以更加轻松地绕过Cloudflare的防护,提高爬取成功率。
提高抓取速度的技巧
除了分布式爬虫系统和穿云API,我们还可以通过一些技术手段来进一步提升抓取速度。例如,我们可以优化HTTP请求,减少不必要的请求头,并使用HTTP压缩来减小传输数据量。此外,异步编程也是提高并发处理能力的有效方法。
本文介绍了如何利用分布式爬虫系统绕过Cloudflare,并提高数据抓取的速度。通过合理地运用分布式系统、模拟真实用户行为、使用IP代理池、以及借助穿云API等工具,我们可以有效地突破Cloudflare的防护,获取所需的数据。然而,在进行数据抓取时,我们一定要遵守相关法律法规,尊重网站的robots.txt协议,避免对目标网站造成过大的负担。




