
数据,已经成为了现代互联网世界最宝贵的资源之一。而对于从事数据挖掘工作的人来说,能够抓取到关键网站上的金融数据,往往意味着能够先人一步,获取到市场的动向和信息。这就像是站在信息的风口浪尖,随时准备冲刺。但与此相对的挑战就是——金融网站的防护越来越严密,尤其是Cloudflare这种全球领先的Web防火墙服务。它就像一道高墙,严密地阻挡了不速之客的入侵。
作为一名从事数据采集的工作人员,我深知突破这道“防线”的困难。但也正因为如此,当我真正掌握了一些有效的方法之后,那份成就感和突破自我的激动,至今仍然无法忘怀。今天,我想和大家分享一些我个人的经验,如何在Cloudflare的保护下,进行金融网站的数据挖掘,轻松绕过反爬机制,获得我们需要的信息。
1. 金融网站的挑战:为什么Cloudflare如此强大?
想必很多从事数据抓取的人都有过这样的经历:你刚进入一个目标网站,准备开始抓取信息,突然就被要求进行验证;或者你打开网页,看到一个难以破解的验证码,心中不禁生疑:“这难道就是所谓的‘防爬’技术?”而背后的真正推手,往往是Cloudflare。
Cloudflare作为全球最为领先的Web安全和性能服务提供商之一,其防护能力是出了名的强大。尤其是对于金融网站,Cloudflare不仅能够有效识别出大规模的恶意访问,还能通过 5秒盾 和 Turnstile CAPTCHA 来阻挡不正常的流量。这种验证机制几乎让所有的自动化爬虫都束手无策。
作为一名数据挖掘从业者,你要面对的并不仅仅是这些复杂的验证程序,更加让人头疼的是如何绕过这些防护机制。面对这些技术,我们究竟如何在不被发现的情况下,继续进行数据抓取?
2. 突破Cloudflare的技术难题:穿云API的完美方案
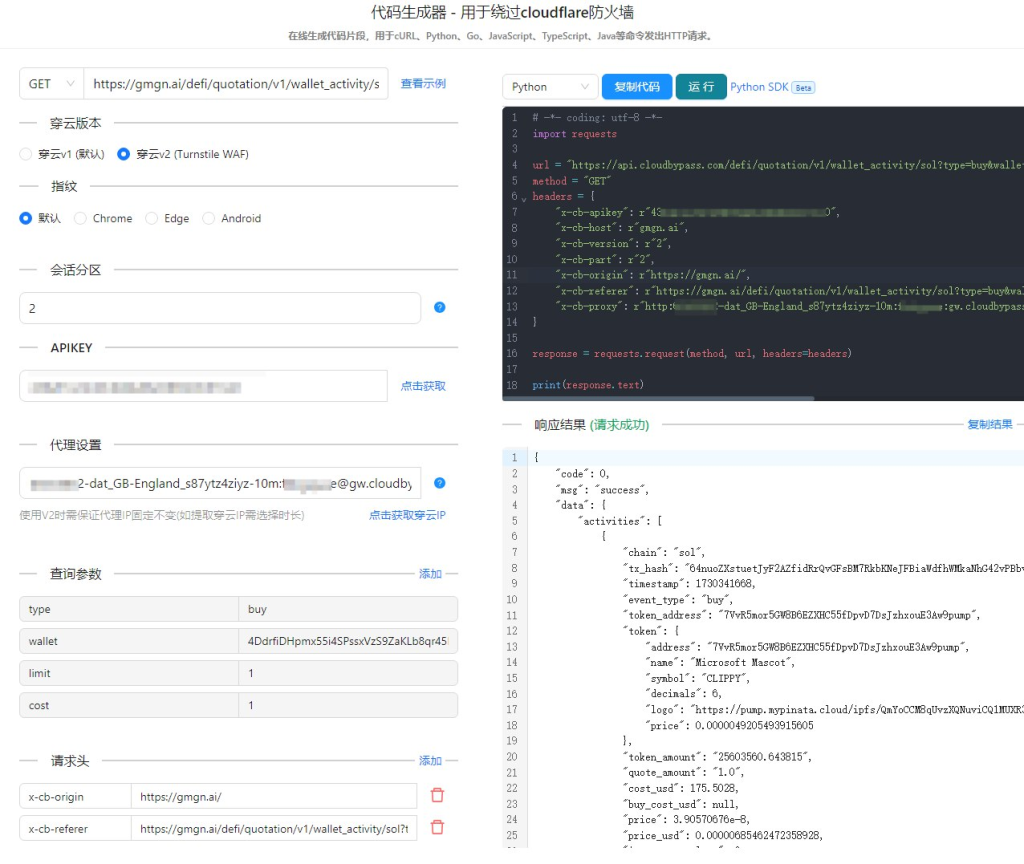
在经历了无数次的尝试后,我最终找到了一个行之有效的方案,那就是 穿云API。穿云API是一款专业的绕过Cloudflare反爬机制的工具,能够有效解决5秒盾、Turnstile CAPTCHA等防护问题,并且通过动态IP代理池,能够稳定绕过Cloudflare的严格审查,顺利获取数据。
2.1 绕过5秒盾与Turnstile CAPTCHA
Cloudflare的5秒盾与Turnstile CAPTCHA是常见的防护措施。尤其是5秒盾,看似简单,但它往往能够轻松识别并阻挡自动化的爬虫行为。而Turnstile CAPTCHA则更加复杂,需要模拟正常用户的点击行为,才能顺利绕过。穿云API正是通过模拟真实用户的访问行为,快速响应并绕过这些复杂的验证,确保数据采集不被打断。
2.2 动态IP池:避免IP封禁
如果没有合适的代理IP池,频繁的请求会让你的IP很快被封禁。这对于金融网站来说尤其重要,因为它们的防护系统会通过大量的请求来识别出异常流量。穿云API通过提供全球高速的S5动态IP代理池,能够智能分配不同的IP地址,从而避免被发现。更重要的是,穿云API的IP池是全球范围的,支持大量国家和地区的IP代理,无论你需要抓取哪个金融网站的资料,都可以通过选择合适的IP来绕过地域限制。
3. 实现无阻碍的数据抓取:穿云API的应用
在穿云API的帮助下,我们不仅可以绕过Cloudflare的防护机制,更能通过一些细致的设置,进一步提高数据抓取的效率。
3.1 设置Referer与浏览器UA
每一个访问请求,都会携带一些浏览器指纹特征,Cloudflare便是通过这些特征来识别请求是否合法。特别是浏览器的UA(User-Agent)和Referer信息,它们几乎是所有防护系统识别请求源的重要依据。
穿云API提供了强大的功能来随机设置Referer和浏览器UA。通过模拟真实用户的行为,每次请求都携带不同的UA和Referer,能够有效迷惑Cloudflare的监控机制,从而避免被封禁。尤其是在金融网站上,UA的设置尤为重要,因为这些网站常常会根据UA来判断访问者的身份。因此,穿云API可以通过设置不同的UA,完美地模拟用户访问行为,从而绕过安全检查。
3.2 Headless浏览器模式
另外,穿云API还支持headless模式,这种模式下,浏览器不会加载图形界面,这样可以大幅度提高数据抓取的速度。而且,在使用headless浏览器时,爬虫的行为与正常用户的浏览行为更加接近,不易被发现。
3.3 无缝集成HTTP API
穿云API的另一个优势是其提供的HTTP API,这让整个数据抓取过程变得更加灵活。通过集成HTTP API,我们能够非常方便地将穿云API与自己的爬虫程序结合,不仅能快速获取数据,还能根据不同的需求调整请求参数、返回数据等。
4. 我的亲身经历:突破Cloudflare的成功案例
曾经,我在一个金融网站上进行数据抓取时,几乎面临过无数次的验证挑战。每当我试图抓取数据时,都会被5秒盾拦截,或者陷入无休止的验证码循环。而这一次,我决定依靠穿云API来帮助我解决这个难题。
我首先通过穿云API设置了动态IP代理池,然后调整了浏览器UA和Referer信息。接着,我配置了API的HTTP请求,启动爬虫程序后,整个抓取过程几乎没有任何阻碍。最令我欣喜的是,数据抓取速度极快且稳定,所有的数据都被顺利采集到。
正是通过穿云API的帮助,我终于能够突破Cloudflare的防护,获得了想要的数据。这次经历让我对数据挖掘的未来充满信心,也让我深刻认识到,正确的工具和技术方案,能够大大提高我们的工作效率和成功率。
5. 结语:突破Cloudflare防护,迎接数据采集新时代
突破Cloudflare防护,对于金融网站的爬虫来说,几乎是一个必经的过程。随着技术的不断进步,穿云API为我们提供了一个高效、安全、稳定的解决方案,让我们能够无阻碍地进行数据采集,获取第一手的市场信息。而随着工具的不断优化,未来的数据抓取将会更加简单和高效。
作为从事数据采集工作的人,我深知其中的挑战,也体会到成功时的兴奋与成就感。如今,凭借穿云API,我们能够突破Cloudflare的防线,走得更远,做得更好。




