互联网已经成为我们生活和工作的重要组成部分。然而,随着网络安全意识的提高,许多网站开始采用各种防护措施来保护自己的数据和用户隐私。Cloudflare作为全球领先的网络安全公司,其防护机制堪称一道坚不可摧的屏障。然而,对于那些需要进行数据采集和竞争情报分析的用户来说,如何绕过Cloudflare的防护成为了一个亟待解决的难题。
1. 遇到Cloudflare防护的困扰
作为一名经常需要进行数据采集的用户,我深知绕过Cloudflare防护的重要性。每当我尝试访问某些网站时,总是会遇到Cloudflare的五秒盾和人机验证,这让我感到无比沮丧。无论是注册新账号还是登录已有账号,Cloudflare的防护机制总是让我的工作陷入困境。
2. 发现穿云API的妙用
在经历了无数次的失败后,我终于发现了穿云API这个神奇的工具。穿云API不仅提供了强大的HTTP API接口,还内置了一站式全球高速S5动态IP代理和爬虫IP池,这让我看到了绕过Cloudflare防护的希望。
3. 穿云API的技术优势
3.1 动态IP代理
穿云API提供的动态IP代理是绕过Cloudflare防护的关键。通过不断变换IP地址,我可以避免被Cloudflare识别为恶意请求。每次请求都会使用不同的IP地址,这使得Cloudflare的防护机制无法锁定我的请求源。
3.2 模拟真实用户行为
穿云API能够模拟真实用户的浏览行为,如鼠标移动、点击和滚动等。这使得Cloudflare的行为分析系统无法识别出我的请求是由爬虫发出的,从而成功绕过了五秒盾的防护。
3.3 突破Turnstile CAPTCHA验证
Turnstile CAPTCHA验证是Cloudflare防护机制中的一大难题。然而,穿云API通过模拟真实用户的行为和动态IP代理,成功突破了Turnstile CAPTCHA验证,让我能够无阻碍地注册和登录目标网站。
4. 实战案例分析
为了更好地理解穿云API的强大功能,我来分享一个实战案例。某次,我需要采集一个竞争对手的价格信息,但该网站使用了Cloudflare的防护机制,传统的爬虫技术无法获取数据。
通过使用穿云API,我成功模拟了真实用户的浏览行为,并通过动态IP地址切换,避免了被Cloudflare识别为恶意请求。最终,我成功获取了竞争对手的价格信息,为公司的市场策略提供了重要参考。
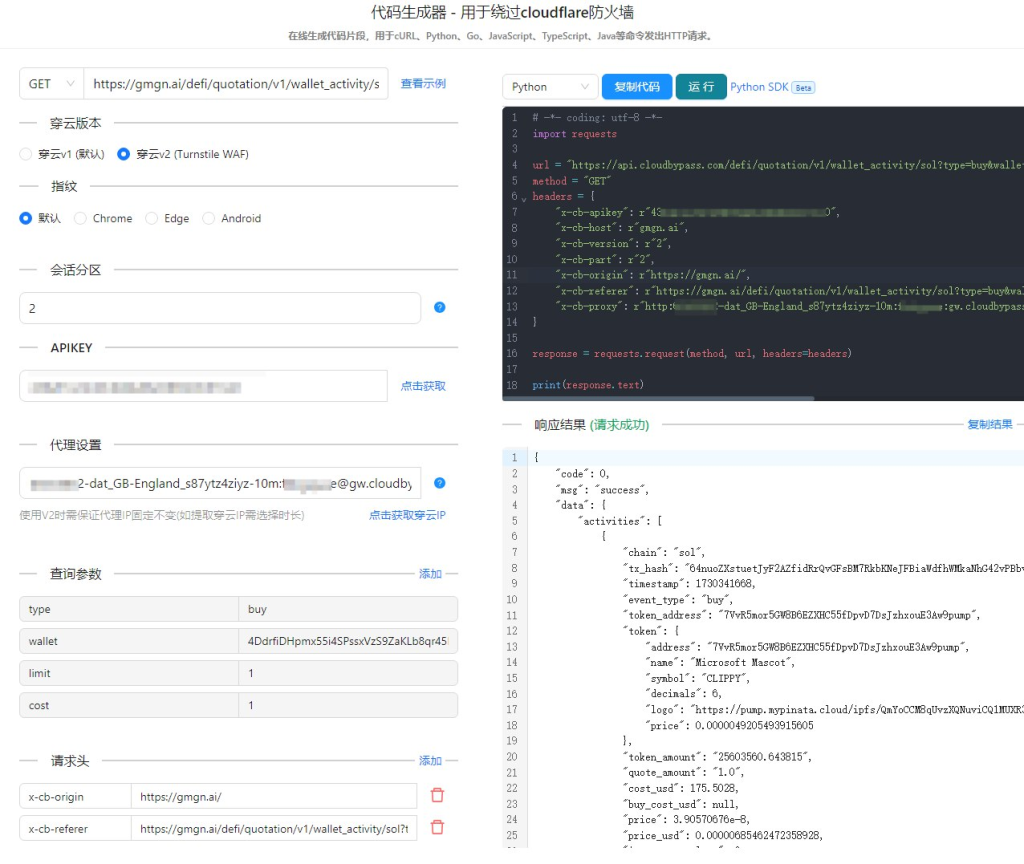
5. 使用穿云API的具体步骤
5.1 接口地址和请求参数
穿云API提供了详细的接口地址和请求参数,使用起来非常方便。以下是一个简单的示例:
import requests
url = "https://api.example.com/data"
params = {
"api_key": "your_api_key",
"target_url": "https://target-website.com"
}
response = requests.get(url, params=params)
data = response.json()5.2 设置Referer和浏览器UA
为了更好地模拟真实用户的行为,穿云API还允许设置Referer和浏览器UA。以下是一个示例:
headers = {
"Referer": "https://example.com",
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/58.0.3029.110 Safari/537.3"
}
response = requests.get(url, headers=headers, params=params)5.3 处理返回数据
穿云API返回的数据格式清晰,易于处理。以下是一个示例:
data = response.json()
print(data)6. 法律与道德的考量
尽管穿云API能够帮助我们绕过Cloudflare的防护,但我们必须时刻铭记法律与道德的底线。未经授权的数据采集行为可能涉及法律风险,因此在进行数据采集时,务必遵守相关法律法规,尊重他人的隐私权。
7. 总结
通过穿云API绕过Cloudflare的防护,是一项技术与智慧的结合。穿云API不仅提供了强大的动态IP代理和模拟真实用户行为的功能,还能够有效突破Turnstile CAPTCHA验证,让我们能够无阻碍地注册和登录目标网站。