
作为一个从事数据抓取的技术人员,我深知面对反爬虫技术的挑战有多么让人头疼。尤其是当你遇到Cloudflare的5秒盾、Turnstile CAPTCHA等严格的人机验证时,往往让你进退两难,甚至一度产生放弃的想法。但今天,我要分享的不是放弃,而是如何通过穿云API突破这些层层防线,轻松抓取动态网页数据,包括获取必要的Cookie信息,让你不再畏惧那些繁琐的验证过程。
1. 为什么需要绕过反爬虫验证?
你可能和我一样,曾经在尝试抓取目标网站数据时,频繁遭遇到Cloudflare的反爬虫屏障——一个5秒钟的等待验证。这段时间仿佛在挑战我的耐心,稍不留神就会被误判为机器人,导致IP被封禁。而更为棘手的,便是那些涉及Turnstile CAPTCHA验证的网页。每次填写验证码,系统总是让我怀疑自己是不是进入了某个迷宫。
然而,作为数据抓取者,我们并不能止步于此。每一次反爬虫验证的背后,都是对我们数据需求的巨大挑战。我深知,掌握合适的技术手段,才能在这些防线中找到突破口。
2. 穿云API——我的秘密武器
穿云API(Chuangyun API)是我用来突破这些防线的得力助手。它提供的服务不仅能够绕过Cloudflare的5秒盾防护,还能有效解决Turnstile CAPTCHA验证问题。通过穿云API,我可以轻松模拟真实用户的行为,不被反爬虫系统检测到,从而顺利抓取动态网页数据,获取所需的Cookie信息。
我第一次使用穿云API时,心情是既激动又忐忑。毕竟,以往每次面对这些验证时,我都需要想尽办法,更有时不得不暂停任务等待“过期”。然而,穿云API让我瞬间改变了抓取策略,带来了前所未有的便捷体验。
3. 穿云API如何绕过Cloudflare 5秒盾和Turnstile CAPTCHA
(1) 绕过Cloudflare 5秒盾
Cloudflare的5秒盾是目前网络上常见的一种反爬虫技术,通常出现在需要保护的高流量网站上。当你尝试访问这些网站时,你会看到一个5秒钟的等待页面,系统在验证请求来源是否合法。这个过程是为了防止恶意抓取工具的攻击。
穿云API通过内置的高速S5动态IP代理池和强大的指纹识别能力,可以模拟真实用户的访问行为,让你“穿透”这个防护层。它会根据你请求的目标网站,自动选择最合适的IP节点和设备特征,从而减少被Cloudflare识别为机器人的概率。
(2) 突破Turnstile CAPTCHA
Turnstile CAPTCHA是Cloudflare推出的一种全新的防护机制,区别于传统的文字验证码,它利用了更为复杂的行为分析算法。通过检测用户的鼠标轨迹、输入节奏等因素,来确认用户是否为机器人。
穿云API通过与全球S5动态IP池结合,在绕过Turnstile CAPTCHA时,提供了完美的解决方案。每当需要输入验证码时,穿云API自动模拟出真实用户的行为路径,迅速避开Turnstile CAPTCHA的限制。通过这种方式,我可以继续抓取目标网站的数据,而不会被误判为机器人。
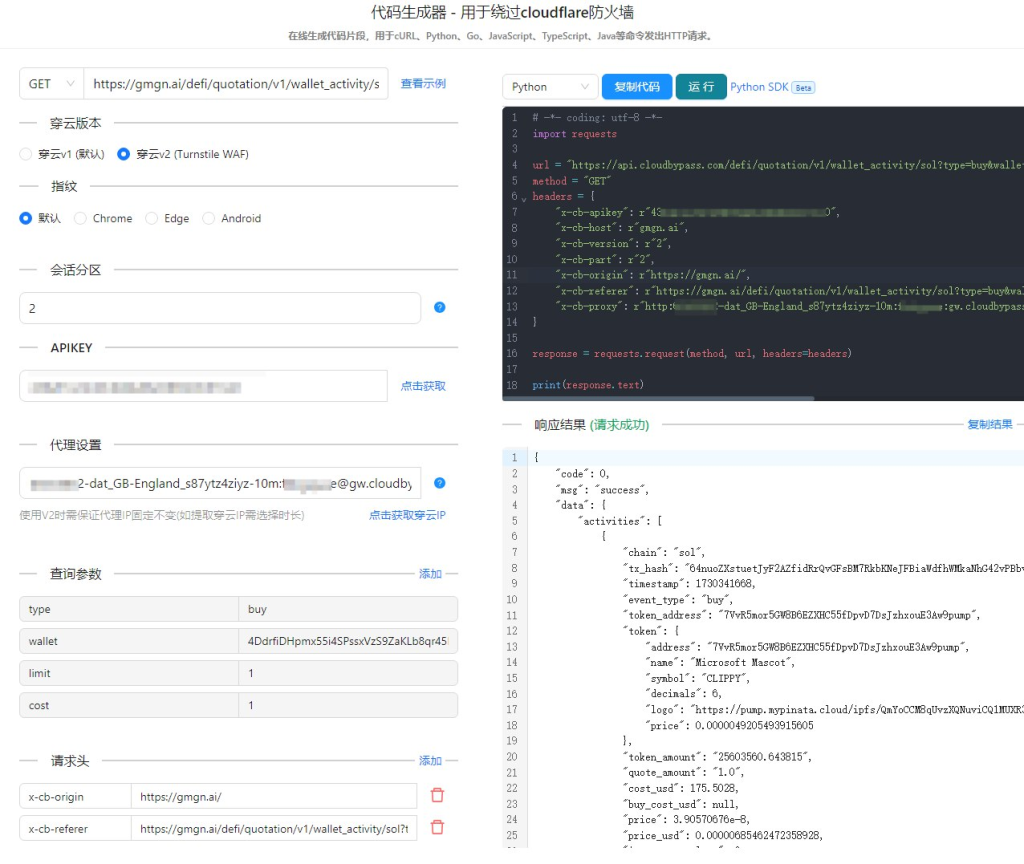
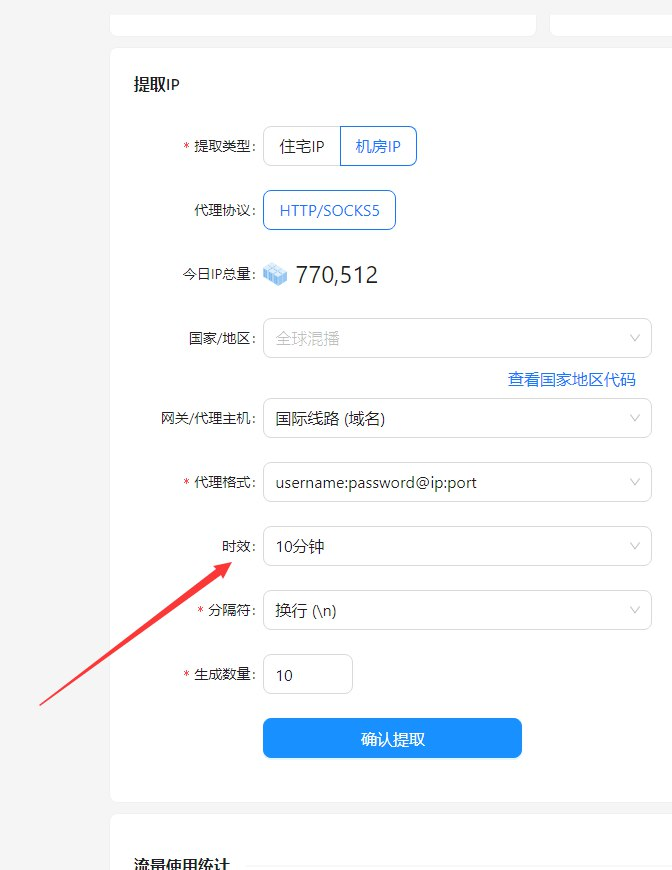
4. 如何使用穿云API获取Cookie
(1) 注册并获取API密钥
首先,你需要注册一个穿云API的账户,并获得API密钥。API密钥是你访问穿云服务的身份认证工具,它将帮助你在后续的请求中验证身份。
(2) 设置请求参数
穿云API提供了详细的文档和示例代码,你只需根据目标网站的要求,设置正确的请求参数即可。以下是我常用的一个请求参数示例:
python复制代码import requests
# 目标网站URL
url = "https://example.com"
# 穿云API请求URL
api_url = "https://api.chuangyun.com/v1/proxy"
# 请求头设置
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.124 Safari/537.36",
"Referer": "https://example.com",
}
# 传入穿云API参数
params = {
"api_key": "your_api_key", # 替换成你的API密钥
"url": url, # 目标URL
"headers": headers, # 自定义请求头
"use_dynamic_ip": True, # 使用动态IP池
}
# 发起请求
response = requests.get(api_url, params=params)
# 解析返回数据
cookie = response.cookies
print(f"Cookie: {cookie}")
(3) 获取并使用Cookie
在成功绕过验证后,穿云API会返回你请求的目标网页数据以及相应的Cookie信息。你可以将这些Cookie信息用于后续的请求,确保你的抓取工作不被中断。
Cookie对于很多动态网页来说是至关重要的,因为它们包含了用户的身份信息和会话数据。通过穿云API获取Cookie后,你可以轻松模拟登录状态,继续抓取其他内容,而无需每次都进行重新验证。
5. 穿云API的优势与应用场景
(1) 无需频繁更换IP
穿云API提供了强大的动态IP池功能,你可以根据需要随时切换IP,避免被目标网站封禁。无论是抓取新闻资讯、商品信息,还是进行SEO监控,穿云API都能为你提供稳定且高效的支持。
(2) 完美支持浏览器指纹
穿云API能够根据目标网站的要求,设置正确的浏览器指纹。你可以指定UA、Referer、Headless状态等参数,使得每次请求看起来都像是一个独立的用户请求,从而避免被识别为机器。
(3) 全球覆盖,稳定高效
穿云API拥有全球覆盖的S5动态IP池,支持200多个国家和地区的IP地址,确保你能够稳定访问不同地区的目标网站。无论是进行跨境电商数据抓取,还是SEO优化监控,穿云API都能提供快速、稳定的服务。
6. 总结
作为一个频繁与反爬虫技术斗智斗勇的抓取者,我深知如何有效绕过防护墙的重要性。穿云API不仅仅是一个简单的抓取工具,它为我提供了突破Cloudflare 5秒盾、绕过Turnstile CAPTCHA验证的强大能力,让我的数据抓取工作变得轻松高效。通过简单的API请求,我能够顺利获取所需的Cookie,并利用动态IP池模拟真实用户行为,避免被目标网站封禁。
如果你和我一样,曾为数据抓取而烦恼,穿云API无疑是你的理想选择。它不仅解决了传统抓取工具难以突破的反爬问题,还提供了稳定可靠的服务,助力你在复杂的网络环境中顺利获取数据,开启全新的数据抓取体验。




