
你是否曾经在爬取一个网站数据时,突然遇到Cloudflare的“五秒盾”?那种等待的痛苦,仿佛进入了一个迷宫,而每一次点击链接都必须耐心等待,甚至每秒都在焦急地想:“我该怎么办?为什么总是被阻挡在外?”
在这个数字化信息飞速流动的时代,获取网络数据已成为日常工作的必需。然而,随着网络安全防护的日益加强,特别是Cloudflare等反爬虫机制的出现,给许多数据抓取者带来了沉重的挑战。更为棘手的是,面对Cloudflare的层层封禁,许多人不得不放弃,或停下脚步。
但不要急,正如一个打击篮球的球员不会因为一次被封盖而放弃进攻,作为一名数据抓取者,你也应该学会如何突破Cloudflare的封锁,利用多线程技术突破它的限制,稳定抓取所需的数据。今天,我将带你一步一步走出困境,让你学会如何构建支持多线程的爬虫,轻松应对Cloudflare封禁,解锁数据获取的全新视角。
一、Cloudflare的五秒盾:为什么你被阻挡?
Cloudflare的五秒盾是许多爬虫开发者的“噩梦”。这种技术旨在识别并阻止恶意流量进入网站。当你访问一个启用了Cloudflare保护的站点时,系统会要求你进行“人机验证”,并在页面上显示一个“5秒等待”页面。这5秒钟,网站会检查你的请求是否符合正常用户行为,比如是否存在IP频繁变化、请求速率过快等异常情况。
如果你只是简单地发送一个请求,Cloudflare会认为你的请求可能来自自动化程序,继而进行拦截,甚至封禁你的IP。这就像你进入一个商场,保安对你进行了严格的检查,确保你不是带着危险的物品或者恶意目的。
二、为什么多线程爬虫是应对Cloudflare封禁的关键?
在传统的爬虫设计中,一般采用单线程爬取网页的方式,这虽然能简单地完成任务,但面对Cloudflare的封禁机制时,单线程的爬虫往往容易被检测到并封禁IP。你每一次发出的请求都会暴露自己的规律,最终遭遇封锁。
多线程爬虫的优势在于,它能够同时发出多个请求,从多个IP或不同线程并发抓取数据,就像一支球队同时发起进攻,每个人的动作不同,防守者难以找出哪个是关键球员。这种分布式的请求方式有效地分散了单个请求的风险,极大提高了突破防护墙的成功率。
在构建支持多线程的爬虫时,你可以通过以下几种方式应对Cloudflare的封禁:
- 多IP代理池:使用动态代理池,模拟多个用户的请求,避免被Cloudflare认定为同一个恶意IP。
- 延迟控制:通过设置请求间隔,模拟人类访问的随机性,避免触发反爬虫系统的警报。
- 合理设置浏览器指纹:伪装请求的设备特征,使得请求看起来更像是真正的用户访问,而不是爬虫程序。
通过这些手段,结合多线程的并发抓取,能够有效减轻Cloudflare的防护压力,提高爬虫稳定性,突破Cloudflare的五秒盾。
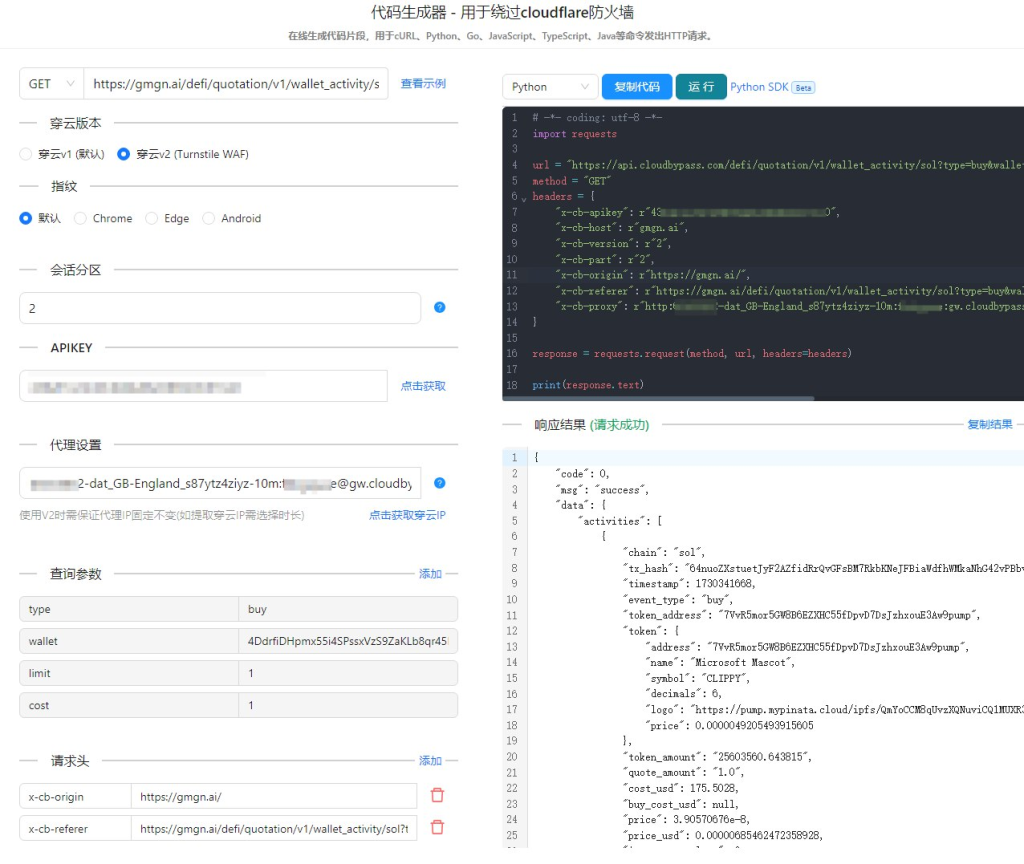
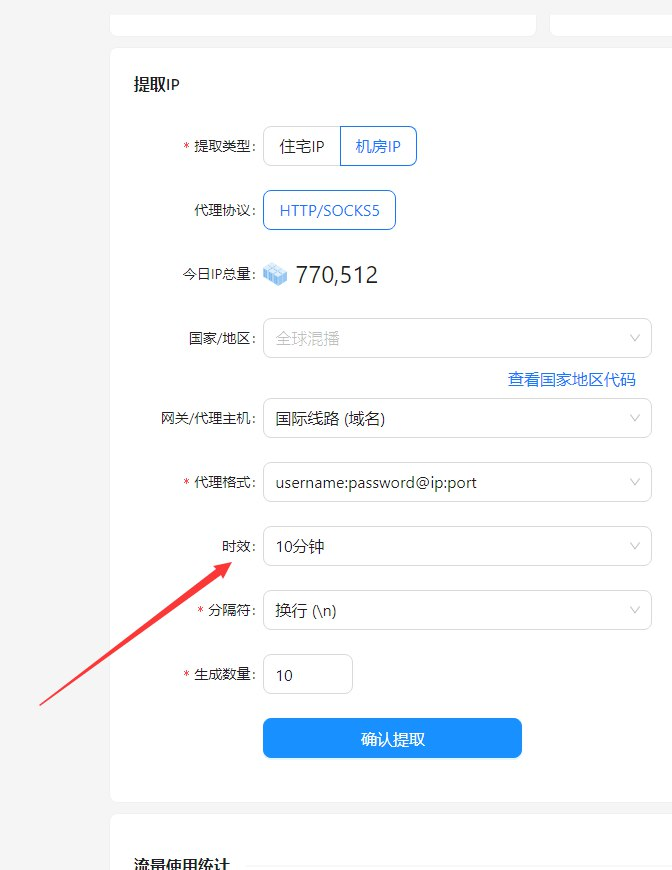
三、穿云API:破解Cloudflare封禁的利器
作为一名经常遭遇Cloudflare封禁的爬虫开发者,我多次寻找解决方案。最终,我发现了穿云API,这是一款针对Cloudflare封禁设计的强力工具。穿云API不仅能够帮助爬虫绕过Cloudflare的五秒盾和验证码,还能提供全球动态IP池,支持多线程并发请求,解决了我在爬虫开发中的诸多难题。
1. 穿云API的优势
- 动态IP池支持:穿云API提供超过350百万的动态IP资源,支持全球范围内的IP节点切换。每次爬取时,系统会随机选择IP,这样就避免了IP封禁问题。
- 突破五秒盾和验证码:穿云API通过模拟真实用户的请求行为,突破Cloudflare的反爬虫机制,轻松绕过五秒盾、人机验证等防护措施。
- 高匿名性和稳定性:穿云API能够提供高度匿名的IP,使得每一次请求都无法被轻易追踪或识别。同时,API支持高并发请求,保证了数据抓取的速度和稳定性。
我使用穿云API时,感觉像是进入了一个可以自由穿行的通道。Cloudflare的五秒盾再也不再是一个无法突破的壁垒,验证码也不再让我苦恼。通过设置合适的请求头、浏览器UA、Referer等参数,结合穿云API提供的动态IP和高并发能力,我能够顺利地抓取目标网站的数据,而不被封禁。
四、如何使用穿云API构建多线程爬虫
接下来,让我们来看看如何通过穿云API构建一个支持多线程的爬虫,并突破Cloudflare的封禁。
(1) 配置穿云API请求
首先,你需要注册穿云API并获得API密钥。然后,通过设置合适的请求参数,创建爬虫任务。以下是一个Python多线程爬虫示例:
python复制代码import threading
import requests
# 穿云API请求URL
api_url = "https://api.chuangyun.com/v1/proxy"
# 目标网址
url = "https://example.com"
# 穿云API密钥
api_key = "your_api_key"
# 请求头设置
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.124 Safari/537.36",
"Referer": "https://example.com",
}
# 请求参数
params = {
"api_key": api_key,
"url": url,
"headers": headers,
"use_dynamic_ip": True, # 使用动态IP池
}
# 爬虫抓取函数
def fetch_data(thread_id):
print(f"Thread-{thread_id} start fetching...")
response = requests.get(api_url, params=params)
print(f"Thread-{thread_id} fetched data: {response.status_code}")
# 处理抓取的数据
# ...
# 创建多个线程来并发抓取数据
threads = []
for i in range(10): # 创建10个线程
thread = threading.Thread(target=fetch_data, args=(i,))
threads.append(thread)
thread.start()
# 等待所有线程结束
for thread in threads:
thread.join()
在这个示例中,我们创建了10个线程来并发抓取目标网站的数据。每个线程都会通过穿云API发出请求,同时使用动态IP池,避免触发Cloudflare的封禁机制。通过并发的方式,可以显著提高数据抓取的速度。
(2) 设置适当的请求延迟
在多线程爬虫中,除了提高并发能力外,还需要合理设置请求延迟,以避免触发反爬虫系统的警报。你可以通过在每个线程中加入随机的延迟时间,模拟用户行为,降低被封禁的风险。
python复制代码import random
import time
def fetch_data_with_delay(thread_id):
time.sleep(random.uniform(1, 3)) # 随机延迟1到3秒
print(f"Thread-{thread_id} start fetching...")
response = requests.get(api_url, params=params)
print(f"Thread-{thread_id} fetched data: {response.status_code}")
通过设置延迟,我们可以更像普通用户一样进行访问,从而减少被识别为爬虫的概率。
五、总结:突破Cloudflare封禁,重获自由
在应对Cloudflare封禁的过程中,绕过Cloudflare的五秒盾和人机验证并不是一项轻松的任务。然而,通过合理运用多线程技术和穿云API提供的强大功能,我们可以有效突破这些防线,稳定获取目标网站的数据。
多线程爬虫能够模拟多个用户的请求,避免暴露单一IP地址。而穿云API的动态IP池和高并发支持,则为我们提供了更强大的抓取能力。在未来的爬虫开发过程中,掌握如何高效构建多线程爬虫,将成为突破Cloudflare封禁的关键。





