
随着网络安全意识的提高,许多网站开始使用Cloudflare等防护服务来保护自己的数据。这给新闻聚合网站的数据采集带来了不小的挑战。如何绕过Cloudflare的防护,实现高效的数据采集,成为了许多技术人员和开发者关注的焦点。
了解Cloudflare的防护机制
Cloudflare是一家提供内容分发网络(CDN)和DDoS防护服务的公司。它通过分布式网络和智能算法,能够有效地防止恶意流量和爬虫攻击。Cloudflare的五秒盾(5-second shield)是其防护机制中的一个重要组成部分,它能够在短时间内识别并阻止可疑的访问请求。
绕过Cloudflare的挑战
对于新闻聚合网站来说,绕过Cloudflare的防护是一个复杂而具有挑战性的任务。传统的爬虫技术在面对Cloudflare的五秒盾时往往显得力不从心。然而,通过一些创新的技术手段和策略,我们可以找到突破口。
1. 模拟真实用户行为
Cloudflare的防护机制之一是识别非人类行为。因此,爬虫需要模拟真实用户的行为,例如随机的点击、滚动和输入等操作。通过这种方式,爬虫可以更好地伪装成真实用户,从而绕过Cloudflare的防护。
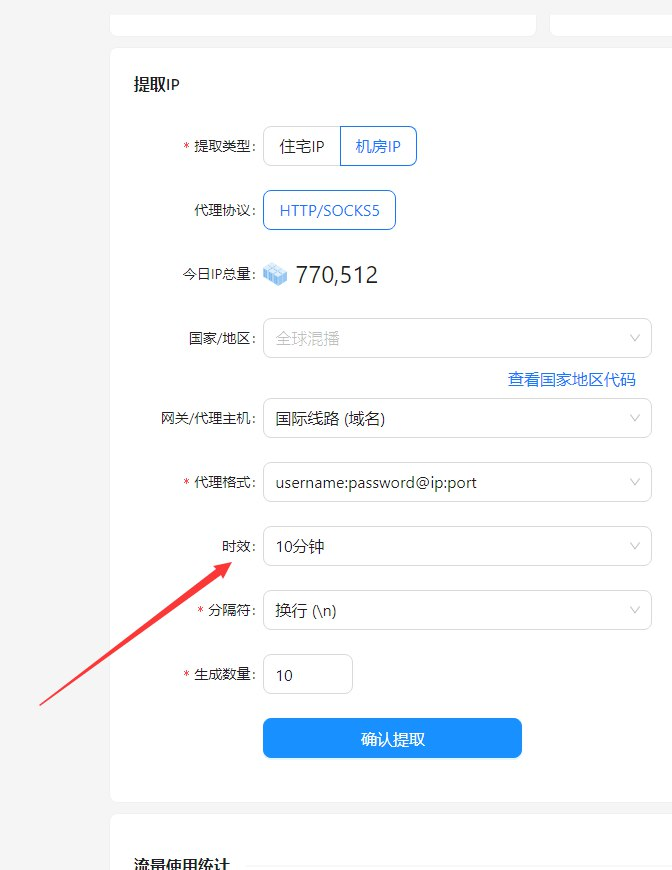
2. 使用代理服务器
代理服务器可以帮助爬虫隐藏其真实IP地址,从而避免被Cloudflare识别和阻止。通过轮换使用不同的代理服务器,爬虫可以更有效地绕过Cloudflare的防护机制。
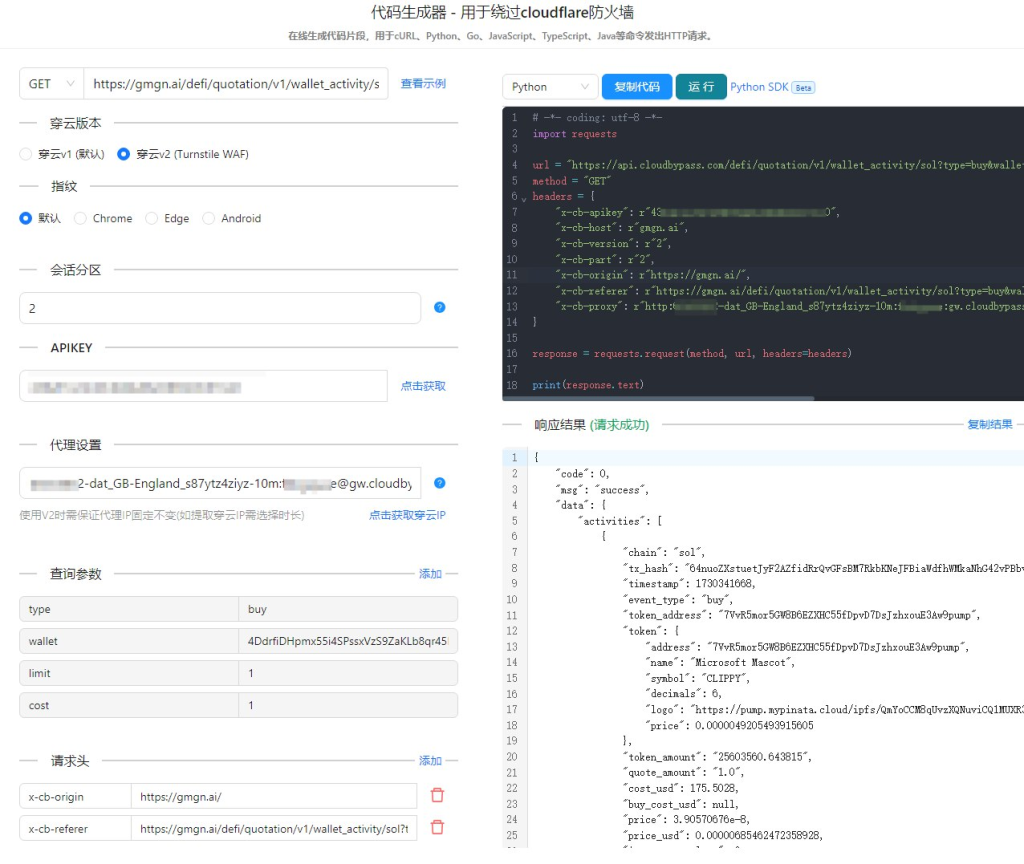
3. 利用穿云API
穿云API是一种专门用于绕过Cloudflare防护的工具。它通过分析Cloudflare的防护机制,提供了一种高效的解决方案。通过使用穿云API,爬虫可以更轻松地绕过Cloudflare的五秒盾,实现高效的数据采集。
实际案例分析
让我们通过一个实际案例来看看如何绕过Cloudflare的防护。假设我们要采集一个受Cloudflare保护的新闻网站的数据。以下是具体步骤:
1. 分析目标网站
首先,我们需要对目标网站进行详细的分析,了解其结构和防护机制。通过浏览器的开发者工具,我们可以查看网站的请求和响应,找到关键的数据接口。
2. 模拟真实用户行为
接下来,我们需要编写爬虫程序,模拟真实用户的行为。例如,爬虫可以随机点击网页上的链接,滚动页面,并在输入框中输入内容。这样可以更好地伪装成真实用户,绕过Cloudflare的防护。
3. 使用代理服务器
为了避免被Cloudflare识别和阻止,我们可以使用代理服务器来隐藏爬虫的真实IP地址。通过轮换使用不同的代理服务器,爬虫可以更有效地绕过Cloudflare的防护机制。
4. 利用穿云API
最后,我们可以使用穿云API来进一步提高爬虫的效率。穿云API通过分析Cloudflare的防护机制,提供了一种高效的解决方案。通过使用穿云API,爬虫可以更轻松地绕过Cloudflare的五秒盾,实现高效的数据采集。
绕过Cloudflare的防护是一个复杂而具有挑战性的任务,但通过模拟真实用户行为、使用代理服务器和利用穿云API等技术手段,我们可以找到突破口。新闻聚合网站在面对Cloudflare的防护时,需要不断创新和优化其数据采集策略,以确保能够高效地获取所需的数据。


