
你是否曾为爬取网站数据而苦恼?当你的爬虫程序一次又一次地被网站的反爬机制拦截时,你是否感到束手无策?这背后的原因可能就在于你的请求不够“真实”。网站会通过分析请求头等信息来判断访问者是真实用户还是爬虫程序。如何让你的请求更像是一个真实的用户发出的,是爬虫开发者需要深入思考的问题。本文将带你深入探索HTTP请求头,揭开模拟真实用户行为的神秘面纱。
HTTP请求头:通往真实世界的钥匙
HTTP请求头是浏览器或其他客户端向服务器发送请求时所携带的一组键值对。这些键值对包含了关于客户端、请求和页面等信息。通过巧妙地配置请求头,我们可以欺骗服务器,使其误以为我们是一个普通的用户。其中,User-Agent、Referer、Cookie等字段尤为重要。
User-Agent:你的身份标识
User-Agent字段表明了发出请求的客户端的身份,包括浏览器类型、版本、操作系统等信息。不同的浏览器、不同的操作系统,其User-Agent是不同的。通过随机选取一个真实的User-Agent,可以增加请求的真实性。
Referer:你从哪里来
Referer字段表示当前请求是从哪个页面链接过来的。合理设置Referer可以模拟用户在网站内的正常浏览行为。
Cookie:你的身份凭证
Cookie是网站服务器存储在用户本地终端上的数据,用于标识用户身份、记录用户状态等。如果能获取到目标网站的Cookie,并将其添加到请求头中,可以模拟登录状态,获取更多的数据。
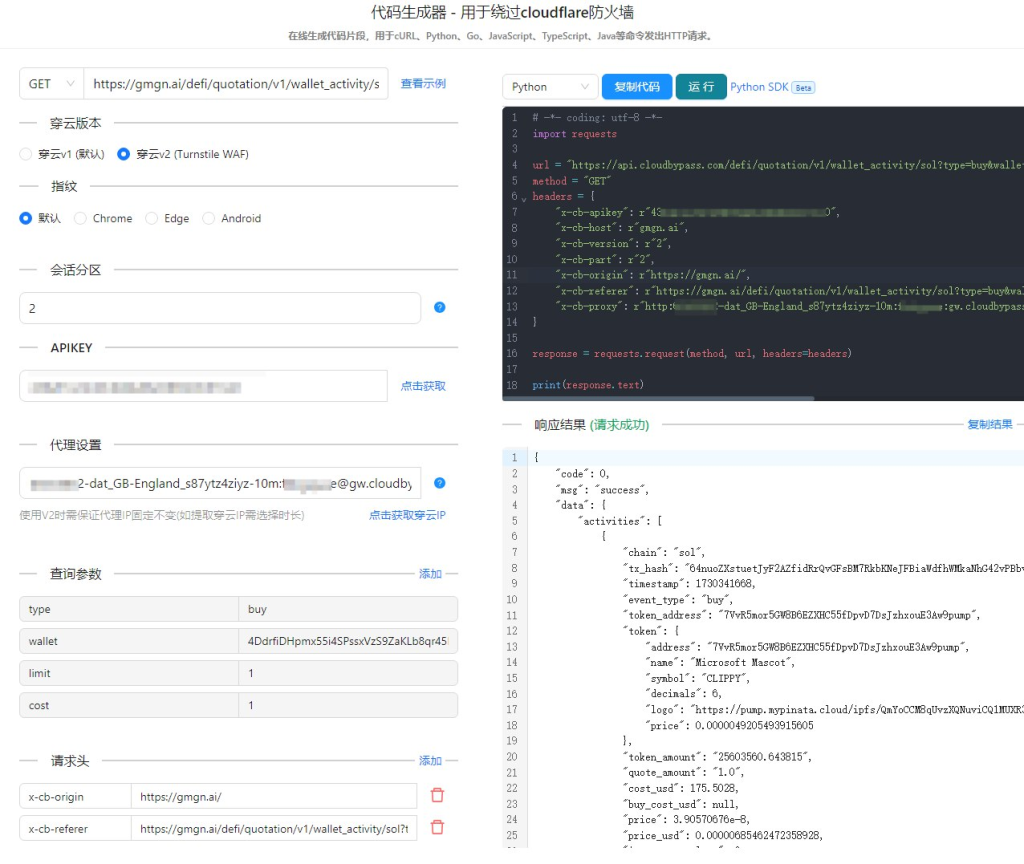
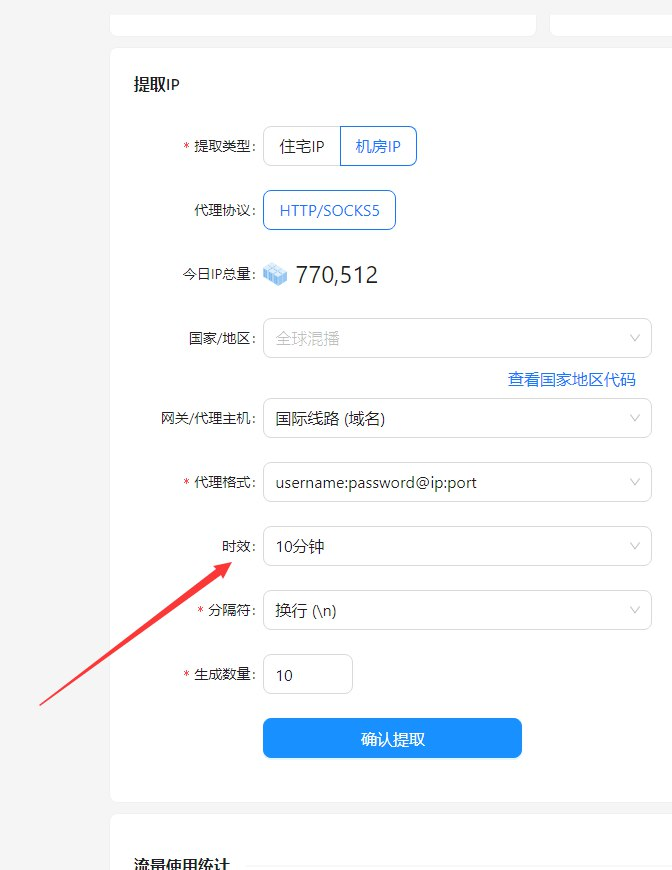
穿云API:模拟真实用户的利器
手动配置请求头是一件繁琐且容易出错的事情。穿云API提供了一套完整的解决方案,可以帮助你轻松地模拟真实用户行为。它支持IP切换、UA伪装、Cookie管理等多种功能,让你无需深入了解HTTP协议的细节,即可实现高效的爬取。
高级技巧:更进一步
除了配置请求头,我们还可以通过一些高级技巧来提高爬虫的隐蔽性。例如,JavaScript渲染、验证码破解、反检测等。这些技巧可以帮助我们应对更复杂的反爬虫机制。
配置HTTP请求头是模拟真实用户行为的重要一环,但并不是万能的。随着反爬虫技术的不断发展,爬虫开发者也需要不断学习和改进自己的技术。通过本文的介绍,相信你对如何配置HTTP请求头有了更深入的了解。在未来的爬虫开发中,你可以结合穿云API等工具,打造出更加强大的爬虫程序。



