在数据密集的商业环境中,数据采集变得越来越关键。然而,众多的网站和平台已经采取了各种反爬虫技术,以防止其内容被大规模地爬取。幸运的是,现代数据采集工具已经武装到了牙齿,穿云API技术可以通过智能代理IP轮换技术来应对这些挑战。那么,如何借助这种方法轻松战胜反爬虫呢?

- 揭开反爬虫的面纱
反爬虫的原理通常围绕对访问者行为的检测。例如,如果短时间内有大量请求从同一IP地址发出,系统可能会判断这是一个爬虫程序在操作,从而触发反爬机制。此外,许多反爬虫技术都会针对爬虫的特定标志,如没有Cookie的请求或使用特定的用户代理来进行拦截。
多种反爬手段,多种策略
1.1 频率限制:对于连续快速的请求,服务器可能会视其为非正常访问行为并加以限制。为此,爬虫可以适当减慢请求速度,或者使用代理IP分散请求。
1.2 用户代理(UA)检测:某些服务器会检查访问者的UA,如果识别为常见的爬虫UA,可能会被拒绝服务。因此,经常更换或伪装用户代理是一种规避方式。
1.3 Cookie验证:一些网站要求请求带有特定的Cookie值才能正常访问。在这种情况下,爬虫需要先进行登录或其他操作,获取到有效的Cookie后再进行数据采集。
- 代理IP轮换的威力
传统的数据采集工具在短时间内大量访问某个网站时,容易被识别并封禁。而智能代理IP轮换可以在每次请求时更换IP地址,有效地模拟成为多个独立的访问者,大大降低了被封禁的风险。
2.1 模拟多用户访问的优越性
智能代理IP轮换的核心优势在于它的能力,模拟数以千计的用户从不同地点进行访问。与单一的IP地址相比,这种策略几乎可以消除单一访问者异常行为模式的风险。而对于目标网站来说,辨识出是一个爬虫工具还是数千名真实用户的访问,变得更为困难。
2.2 减缓封禁影响的策略
即使最先进的数据采集工具也难以避免一些IP地址被封禁,但代理IP轮换策略的妙处在于,即使部分IP地址受到限制,其他的代理IP仍然可以继续工作。这种冗余性确保了数据采集活动的连续性和稳定性,让工作不受干扰。
- 超越常规的代理服务
不同于传统代理服务,智能代理IP轮换工具利用了庞大的IP池,包括多个国家和地区,确保了IP的多样性和真实性。这意味着每次轮换都能够获得一个全新的、未被封禁的IP地址,使数据采集更加稳定。
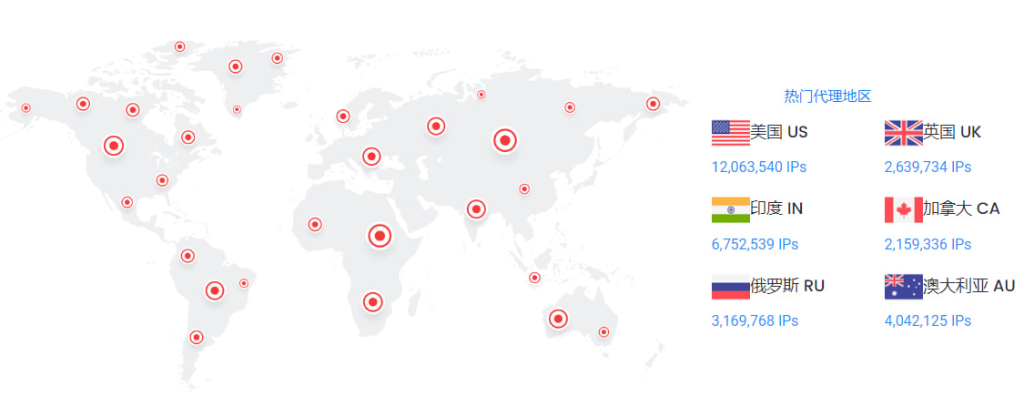
3.1 庞大的IP库提供无尽选择
对于数据采集者来说,拥有广泛的IP资源是他们最大的武器之一。通过访问来自各种国家和地区的IP,智能代理IP轮换工具确保每次的访问都像真实用户一样,这样即使一些IP遭到封禁,仍有大量备用选项可供使用,维持了采集活动的连续性。
3.2 IP的真实性和多样性为关键
仅仅拥有大量的IP还不够,其真实性和多样性也是至关重要的。通过模拟不同地区的真实用户访问,智能代理IP轮换工具可以成功地绕过大多数基于地理位置的访问限制,同时也可以避免因为使用低质量代理IP而导致的数据错误或遗漏。
- 适应性与灵活性
随着网站的反爬虫技术不断升级,智能代理IP轮换工具也在不断进化,以适应各种新的挑战。它能够识别网站的封禁策略,并实时调整其策略,确保数据采集不受中断。
4.1 实时监测与策略调整
智能代理IP轮换工具的一个核心优势在于其能够持续监测各种网站的行为和响应。当工具检测到可能的封禁迹象或异常响应时,它会立即调整其使用的IP或请求策略,减少被识别的风险。
4.2 模块化策略设计
适应性也意味着工具能够为不同类型的网站提供个性化的数据采集策略。通过模块化的策略设计,智能代理IP轮换工具可以根据网站的具体特点和其反爬虫机制,选择最合适的访问模式和频率,从而确保数据的准确性和完整性。
- 人类行为模拟
除了IP轮换外,先进的数据采集工具还能模拟真实的用户行为,如滚动、点击和搜索,进一步迷惑目标网站,使其难以识别出采集行为。
5.1 行为逻辑编排
真正区别人类和机器的是行为模式的随机性与逻辑性。先进的数据采集工具在模拟时,不仅仅是简单地进行点击和滚动,而是根据真实用户行为数据进行编排,如页面停留时间、随机的滚动速度和深度、甚至模拟鼠标的非线性移动轨迹。这种近乎完美的模拟使得工具的行为更加接近真实用户,从而大大降低了被识别的风险。
5.2 交互元素的多样化模拟
真实的用户行为不止于简单的页面浏览。他们可能会在搜索框中输入关键词、对感兴趣的内容进行点击或是填写某些表单。先进的数据采集工具也将这些交互元素纳入模拟范畴,进一步加深了对真实用户的模拟,使其行为更难以被检测出。
结论:智能代理IP轮换不仅仅是一种技术手段,更是数据采集领域的一次颠覆性创新。它确保了数据采集的持续性和稳定性,为研究者和企业在这个数据驱动的时代中提供了有力的支持。





