
作为一名数据采集工作者,我深知在瞬息万变的数字世界里,获取准确、及时的数据是多么重要。然而,越来越多的网站为了保护自身数据,纷纷设置了强大的反爬虫机制,其中Cloudflare的5秒盾人机验证和Turnstile CAPTCHA验证更是让无数爬虫工程师头疼不已。
痛点:反爬虫机制的层层阻碍
在从事加密交易数据采集的过程中,我曾无数次被这些反爬虫机制挡在门外。Cloudflare的5秒盾人机验证,就像一道坚固的城墙,阻挡着我获取数据的脚步。每次想要绕过这道墙,都需要耗费大量的时间和精力,而且成功率并不高。而Turnstile CAPTCHA验证更是变幻莫测,让人防不胜防。
转机:穿云API的横空出世
就在我感到束手无策的时候,我发现了穿云API这个强大的工具。穿云API号称能够轻松绕过Cloudflare的反爬虫机制,包括5秒盾人机验证和Turnstile CAPTCHA验证。抱着试一试的心态,我开始深入研究和使用穿云API。
穿云API的强大功能
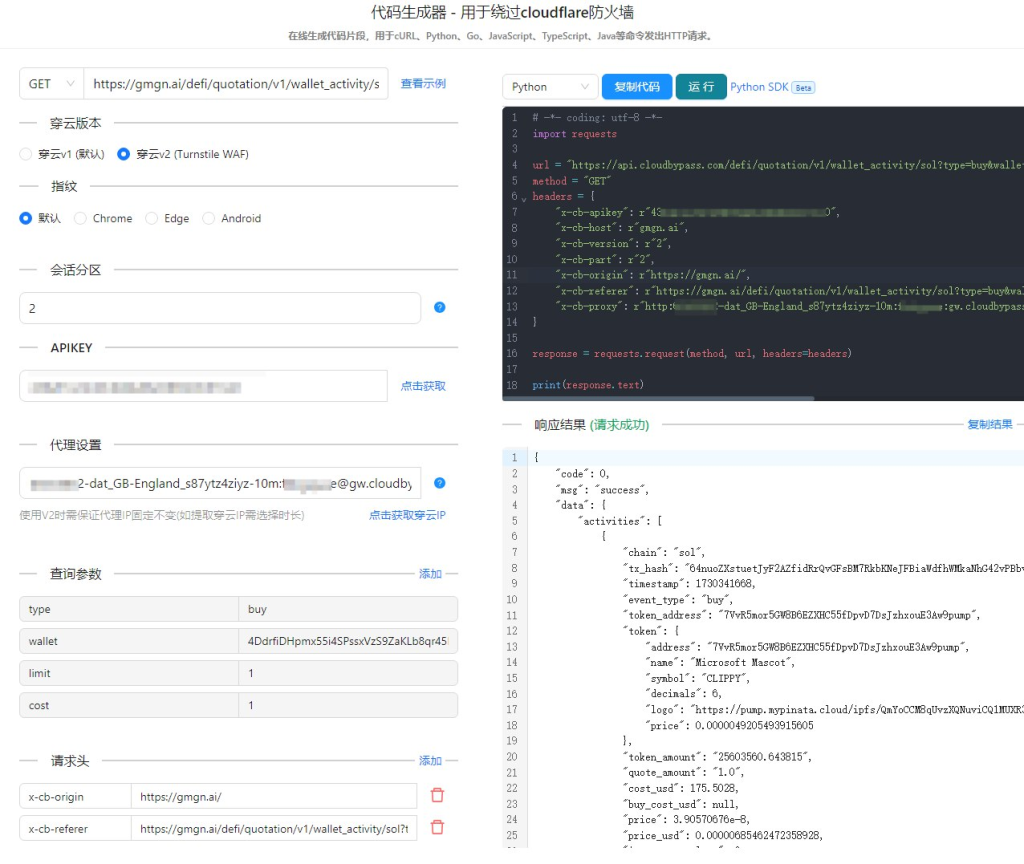
穿云API提供了HTTP API和内置一站式全球高速S5动态IP代理/爬虫IP池,让我能够轻松地定制化我的爬虫请求。通过设置Referer、浏览器UA和headless状态等浏览器指纹设备特征,我可以模拟真实用户的行为,成功绕过Cloudflare的检测。
- HTTP API: 穿云API提供了简单易用的HTTP API,让我可以方便地将API集成到我的爬虫程序中。通过调用API接口,我可以轻松获取到目标网站的页面内容。
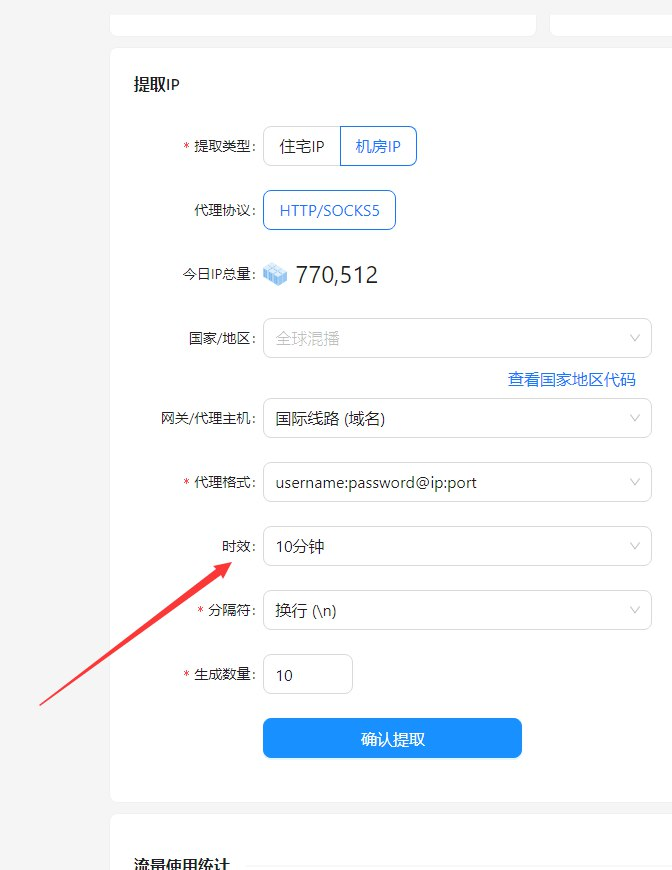
- S5动态IP代理: 穿云API的S5动态IP代理池,为我提供了海量的IP资源。我可以根据需要选择不同的IP,从而有效地分散风险,提高爬虫的稳定性。
- 灵活配置: 穿云API支持自定义各种浏览器指纹特征,让我可以根据不同的网站设置不同的请求头,从而更好地模拟真实用户的行为。
实战应用:成功突破反爬虫
在使用穿云API的过程中,我成功地绕过了多个加密交易所的Cloudflare反爬虫机制。通过设置合理的请求频率、随机化User-Agent、以及使用住宅IP,我能够稳定地获取到所需的数据。
情感描写:从绝望到惊喜
当我第一次成功绕过Cloudflare的5秒盾人机验证时,我感到无比的兴奋。那种感觉就像是一名探险家,终于找到了通往宝藏的密道。穿云API让我从一个被反爬虫机制困扰的爬虫工程师,变成了一个能够自由获取数据的“数据大盗”。
总结:穿云API是数据采集工作者的福音
穿云API的出现,无疑为广大数据采集工作者带来了福音。它不仅大大降低了我们绕过反爬虫机制的门槛,而且还提高了我们的工作效率。如果你也像我一样,在数据采集的过程中遇到困难,那么我强烈建议你尝试一下穿云API。
随着技术的不断发展,反爬虫机制也会变得越来越复杂。但是,我相信,像穿云API这样的工具会不断进化,为我们提供更强大的支持。我期待着未来能够有更多像穿云API这样的工具出现,帮助我们更好地应对各种挑战,获取到我们想要的数据。
在数据驱动的时代,数据就是生产力。穿云API作为一款强大的数据采集工具,帮助我实现了数据的自由获取。我相信,它也会帮助更多的开发者和研究人员,在各自的领域取得更大的成就。





