作为一名高度依赖数据驱动的业务人员,我深知高质量数据的价值。然而,在爬取数据时,Cloudflare这道坚固的城墙常常让我望而却步。5秒盾人机验证、Turnstile CAPTCHA,这些反爬措施就像是一道道关卡,阻碍着我获取数据的步伐。
初遇Cloudflare:绝望与希望
第一次尝试爬取一个竞争对手的网站时,我信心满满。然而,Cloudflare的5秒盾瞬间把我打回了现实。无论我如何调整爬虫程序,都无法绕过这道验证。那种感觉,就像是一拳打在了棉花上,既无力又沮丧。
就在我几乎要放弃的时候,我遇到了穿云API。抱着试一试的心态,我开始深入了解这个工具。
穿云API:我的数据采集“利器”
穿云API就像是一把锋利的匕首,精准地刺穿了Cloudflare的防御。它不仅能轻松绕过5秒盾,还能突破Turnstile CAPTCHA,让我畅通无阻地访问目标网站。
动态更新请求参数:让爬虫更“聪明”
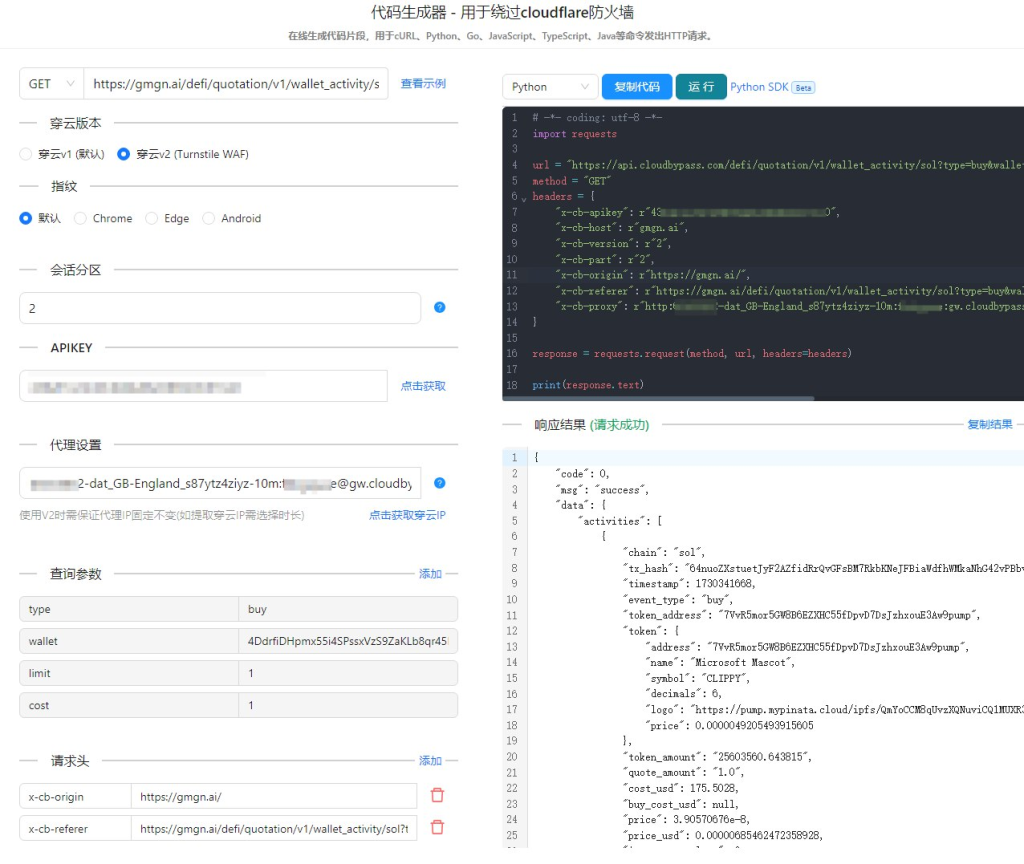
穿云API最让我惊艳的功能之一就是动态更新请求参数。以往,我的爬虫程序总是使用固定的请求头和IP,很容易被Cloudflare识别出来。而穿云API内置的全球高速S5动态IP代理池,让我可以随时更换IP,搭配上随机生成的Referer、浏览器UA和headless状态,我的爬虫程序变得更加“聪明”,更像是一个真实的用户。
HTTP API:简单易用,高效灵活
穿云API提供的HTTP API接口非常友好,即使没有很强的编程基础,我也能很快上手。接口地址、请求参数、返回处理都清晰明了,让我可以轻松地将它集成到我的爬虫程序中。
实战案例:竞品分析的“秘密武器”
通过穿云API,我成功地对多个竞争对手的网站进行了深入的分析。我获取了他们的产品信息、价格、销量、评论等大量数据,并对这些数据进行了深入挖掘和分析。这些数据为我提供了宝贵的决策依据,帮助我制定了更加有效的营销策略。
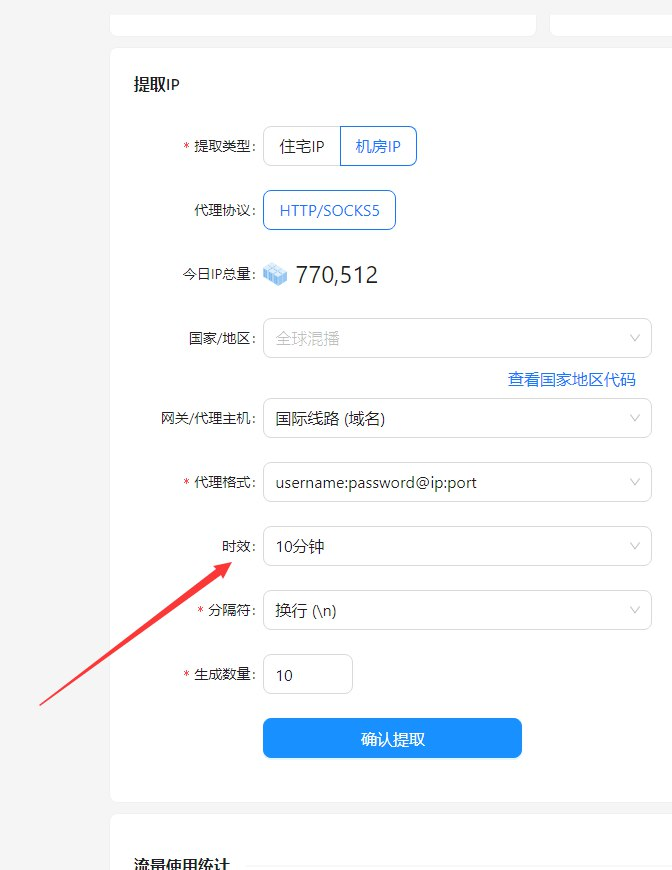
IP质量的重要性:稳定、高速、多样化
作为一名对IP质量有较高要求的用户,我深知IP的稳定性、速度和多样性对爬虫的重要性。穿云API提供的IP质量非常高,稳定性好,速度快,而且IP池非常庞大,能够满足我多样化的需求。
结语:数据采集,永无止境
数据采集是一场永无止境的探索。穿云API的出现,无疑为我们打开了一扇新的大门。它让我们能够更轻松地获取到我们想要的数据,为我们的工作和生活带来更多的便利。
给想成为数据采集“高手”的你的一些建议:
- 不断学习: 数据采集技术日新月异,只有不断学习,才能跟上时代的步伐。
- 实践出真知: 多动手实践,才能真正掌握数据采集的技巧。
- 遵守法律法规: 在进行数据采集时,一定要遵守相关的法律法规,尊重网站的版权。
最后,我想说: 数据是宝藏,但也是一把双刃剑。我们应该合理利用数据,为社会创造更多的价值。