
作为一名旅行行业的从业者,我深知数据的重要性。无论是制定个性化的旅行路线,还是分析市场趋势,都需要大量的数据支撑。然而,在获取这些数据时,我遇到了一个巨大的拦路虎——Cloudflare。
爬虫之路的艰辛
还记得我第一次尝试从一家OTA网站上爬取酒店价格数据时的情形吗?满怀信心地写好爬虫代码,却总是被Cloudflare的5秒盾人机验证挡在门外。我尝试过各种方法:更换IP、伪装浏览器指纹、甚至手动输入验证码,但都无济于事。那种眼睁睁看着数据就在眼前,却无法触碰的挫败感,让我一度想要放弃。
穿云API:我的旅行数据“护照”
就在我彷徨无助的时候,我遇到了穿云API。一开始,我对这个工具也抱有怀疑态度,毕竟市面上号称能破解Cloudflare的工具并不少。但是,经过一番深入的了解和实操,我发现穿云API确实是一款“神器”,它不仅能轻松绕过Cloudflare的5秒盾人机验证,还能突破Turnstile CAPTCHA,让我能够无阻碍地访问目标网站,获取到我想要的数据。
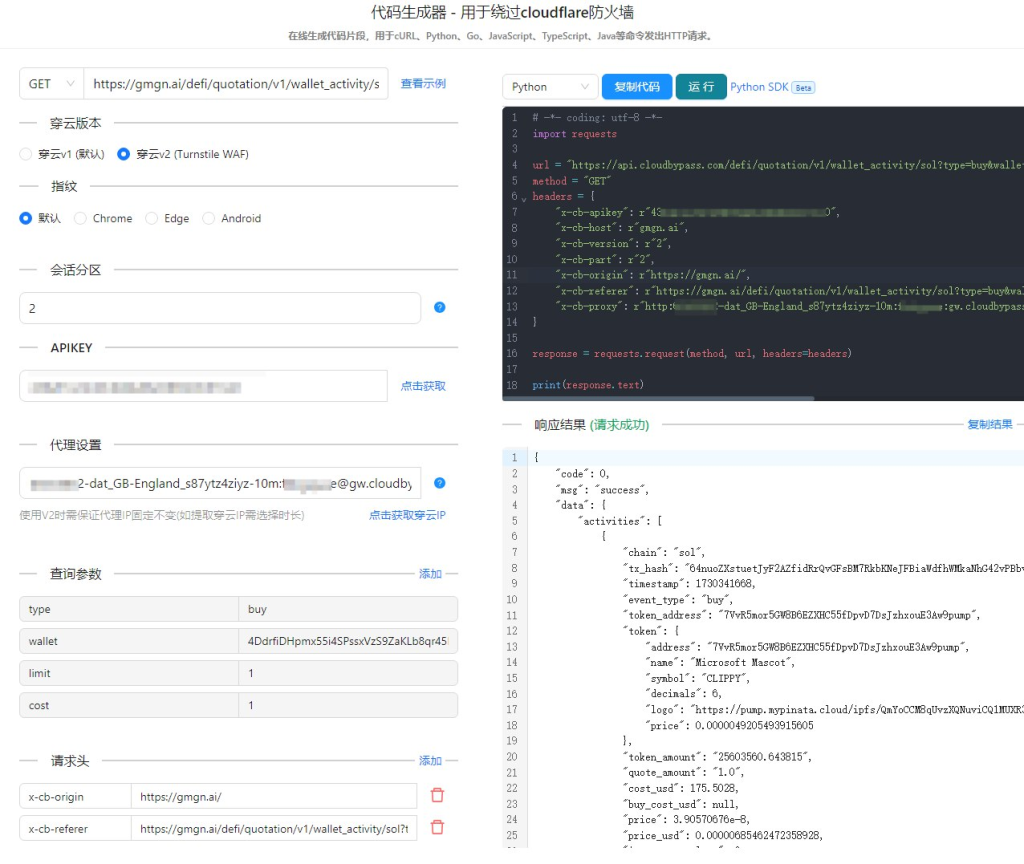
穿云API的强大之处
穿云API之所以能如此强大,主要归功于以下几个方面:
- HTTP API和动态IP代理: 穿云API提供了简单易用的HTTP API接口,让我可以像调用普通函数一样发送请求。同时,它还内置了一站式全球高速S5动态IP代理/爬虫IP池,能够有效地隐藏我的真实IP,避免被网站封禁。
- 丰富的配置选项: 穿云API支持设置Referer、浏览器UA和headless状态等各种浏览器指纹设备特征,让我可以模拟不同的用户行为,从而更有效地绕过Cloudflare的检测。
- 强大的抗干扰能力: 穿云API经过了大量的测试和优化,能够很好地应对Cloudflare的各种反爬虫策略,如JS混淆、参数加密等。
实战案例:如何获取全球酒店价格数据
下面,我以一个具体的例子来说明如何使用穿云API来爬取全球酒店价格数据。
Python
import requests
from cloudbypass import CloudBypass
# 创建一个穿云API实例
cb = CloudBypass()
# 设置请求参数
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/112.0.0.0 Safari/537.36'
}
url = 'https://www.booking.com/searchresults.html?dest_id=620854&checkin_date=2024-12-25&checkout_date=2025-01-01&group_adults=2&no_rooms=1'
# 发送请求
response = cb.get(url, headers=headers)
# 处理响应
if response.status_code == 200:
# 解析HTML,提取酒店价格数据
# ...
else:
print('请求失败')
如上所示,我只需要创建一个CloudBypass实例,然后设置好请求参数,就可以轻松地发送请求并获取到酒店价格数据了。整个过程非常简单,即使没有太多的编程经验,也可以很快上手。
穿云API给我的启示
通过使用穿云API,我终于可以畅通无阻地获取到全球酒店价格数据了。这不仅让我能够更准确地分析市场行情,为客户制定更具性价比的旅行计划,还让我对数据采集工作充满了新的热情。
穿云API教会了我,在数据的世界里,没有什么是不可能的。 只要我们掌握了正确的工具和方法,就能轻松地突破各种限制,获取到我们想要的数据。同时,穿云API也让我认识到,数据是旅行行业发展的基石。只有充分利用数据,我们才能更好地满足客户的需求,提升服务质量。
Cloudflare的出现,无疑给数据采集工作带来了巨大的挑战。但是,随着技术的不断发展,我们也拥有了越来越多的工具来应对这些挑战。穿云API就是其中之一。它不仅能帮助我们绕过Cloudflare的各种防护,还能为我们提供一个稳定可靠的数据采集平台。如果你也从事旅游行业,或者从事其他需要大量数据的行业,不妨试试穿云API,相信它会成为你工作中的得力助手。




