
在数据驱动的时代,数据挖掘已经成为企业获取竞争优势的重要手段。然而,许多网站,尤其是电商平台,为了保护自身数据,部署了强大的反爬虫机制,如Cloudflare。这给数据采集工作带来了巨大的挑战。那么,如何才能在绕过Cloudflare的同时,最大程度地降低被封禁的风险呢?
Cloudflare为何如此难缠?
Cloudflare作为一款强大的CDN和安全服务,为网站提供了全方位的保护。它通过以下方式来识别并阻止爬虫:
- 行为分析: Cloudflare会分析用户的请求频率、请求方式、UA等信息,一旦发现异常,就会触发防护机制。
- 验证码挑战: 对于疑似爬虫的请求,Cloudflare会弹出验证码,要求用户验证身份。
- IP封禁: 对于多次违规的IP,Cloudflare会直接封禁。
绕过Cloudflare的常见方法及风险
1. 模拟人工操作
- 更换User-Agent: 伪装成不同的浏览器。
- 随机延时: 模仿人类的思考时间。
- 动态IP: 不断更换IP地址。
风险: 虽然这些方法有一定效果,但Cloudflare的检测机制也在不断升级,单一的模拟行为很容易被识别。
2. 代理IP
- 隐藏真实IP: 通过代理服务器来隐藏自己的真实IP。
风险: 公共代理IP往往共享性高,容易被Cloudflare标记。
3. 无头浏览器
- 模拟浏览器环境: 使用无头浏览器来执行JavaScript,绕过一些JavaScript防护。
风险: 无头浏览器虽然强大,但配置复杂,且容易被Cloudflare识别。
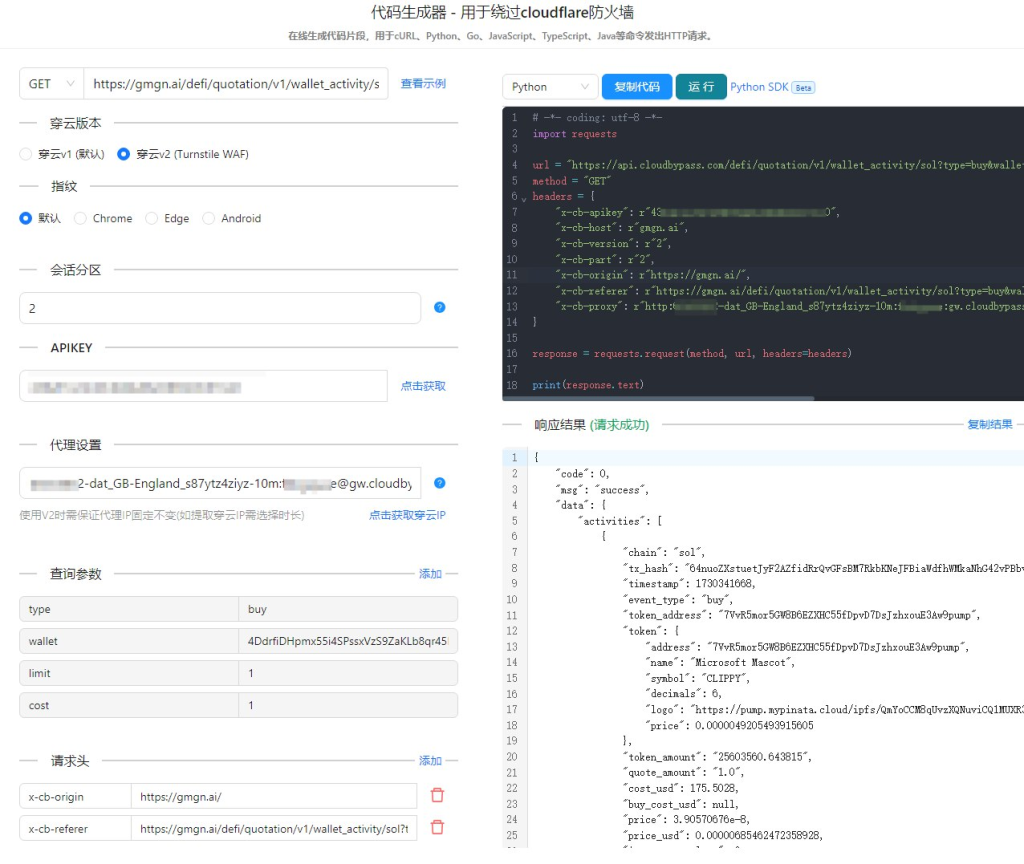
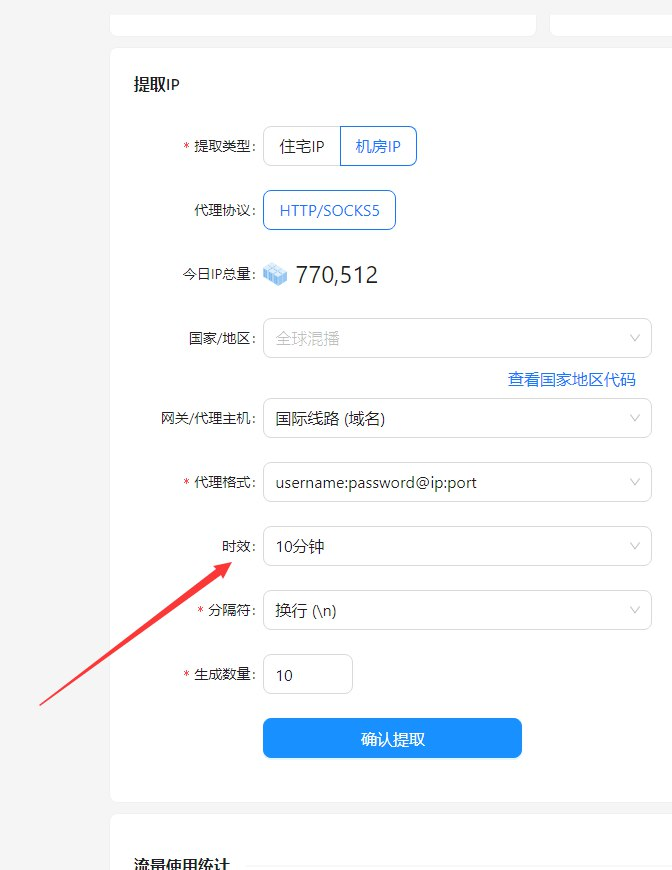
如何降低被封禁的风险?
1. 选择专业的API服务
- 穿云API:作为一款专业的API服务,穿云API集成了多种反反爬虫技术,可以帮助用户轻松绕过Cloudflare的防护。它通过以下方式降低被封禁的风险:
- 海量IP池: 提供全球范围内的动态住宅IP,有效分散风险。
- 智能旋转代理: 根据实时情况,智能切换代理IP。
- 验证码识别: 自动识别并破解各种验证码。
- JavaScript渲染: 执行页面上的JavaScript代码,获取完整页面内容。
2. 合理设置爬取频率
- 模拟人类行为: 爬取频率不要过于密集,避免被Cloudflare识别为爬虫。
- 动态调整频率: 根据网站的负载情况,动态调整爬取频率。
3. 遵守robots协议
- 尊重网站规则: 遵守网站的robots协议,避免爬取被禁止的内容。
4. 监控并及时调整
- 实时监控: 定期监控爬取状态,及时发现并解决问题。
- 调整策略: 根据网站的防护策略调整爬取策略。
绕过Cloudflare并非易事,需要综合运用多种技术手段。穿云API作为一款专业的API服务,可以大大降低被封禁的风险,提高数据采集的效率。然而,我们也需要注意,数据采集一定要合法合规,尊重网站的规则。




