
作为一名数据分析师,我经常需要从各种网站爬取数据。但令人头疼的是,越来越多的网站,尤其是那些有价值的网站,都部署了强大的反爬虫机制,其中Cloudflare无疑是最棘手的对手之一。
每当我兴致勃勃地准备开始一次新的爬取任务时,总会遇到各种各样的阻碍:5秒盾让我望而却步,人机验证让我抓狂,WAF防护更是让我屡屡碰壁。那种眼睁睁看着目标数据却无法获取的挫败感,真的让人欲哭无泪。
穿云API:我的爬虫利器
就在我快要放弃的时候,我发现了穿云API这个神器。刚开始,我抱着试试看的心态,抱着它就像抱着救命稻草一般。没想到,它真的让我看到了希望。
穿云API就像一把万能钥匙,轻而易举地帮我打开了Cloudflare设置的重重关卡。5秒盾?不存在的!人机验证?小菜一碟!WAF防护?形同虚设!我仿佛看到了一条通往数据海洋的康庄大道。
最让我惊喜的是,穿云API提供了非常丰富的功能。HTTP API让我可以轻松地将它集成到我的爬虫程序中,S5动态IP代理则让我可以随意切换IP,避免被网站封禁。而且,它还支持自定义Referer、浏览器UA和headless状态等,让我可以更好地模拟真实用户行为。
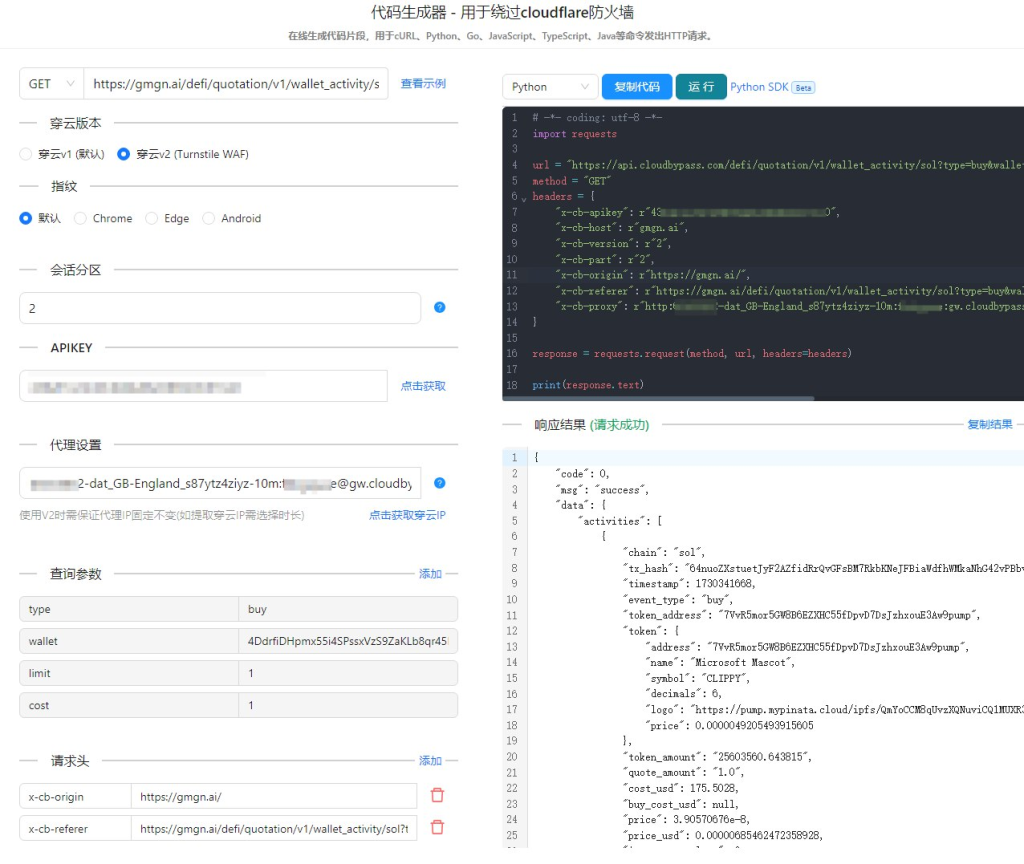
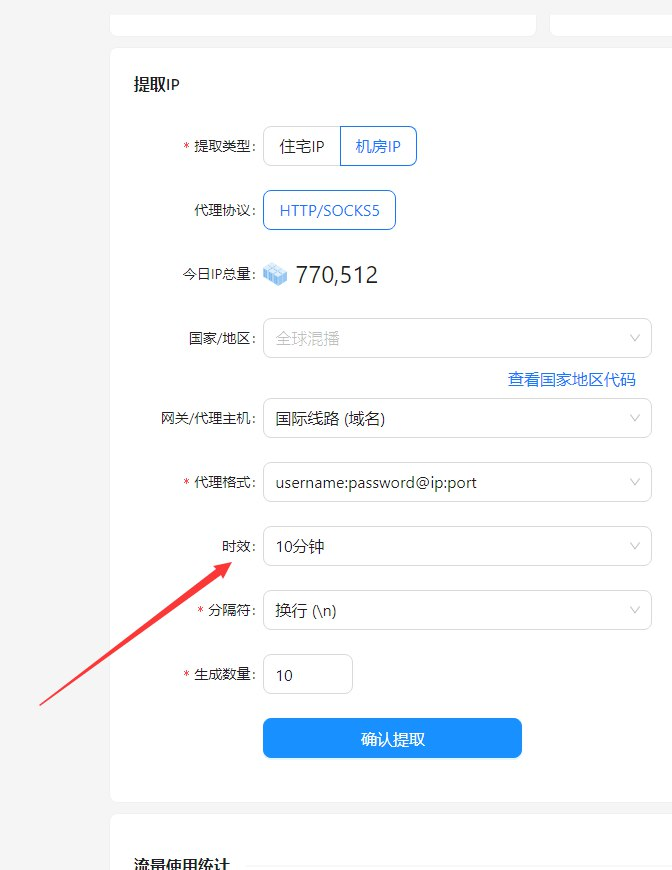
穿云API如何帮我解决问题
- 绕过5秒盾: 穿云API通过智能路由和动态IP切换,轻松绕过Cloudflare的5秒盾,让我可以快速访问目标网站。
- 突破人机验证: 穿云API内置了强大的验证码识别功能,可以自动识别并解决各种类型的人机验证,大大提高了我的爬取效率。
- 绕过WAF防护: 穿云API通过模拟真实用户行为,成功绕过了WAF的检测,让我可以自由地爬取数据。
- 无阻碍访问: 借助穿云API,我终于可以无阻碍地访问那些曾经令我望而却步的网站,获取到我需要的数据。
穿云API给我的启示
通过使用穿云API,我深刻体会到,在与网站反爬虫的斗争中,我们不能一味地蛮干,而是需要借助科学的方法和工具。穿云API就是一个很好的例子,它不仅让我顺利完成了爬取任务,还让我对爬虫技术有了更深入的了解。
**对于那些还在为爬虫而苦恼的朋友们,我强烈推荐穿云API。**它不仅是一款功能强大的工具,更是一个值得信赖的伙伴。有了它的帮助,你将会发现,爬虫的世界其实并没有想象中那么难。
爬虫之路漫漫,但只要我们不断探索,不断学习,就一定能找到属于自己的解决方案。穿云API只是我爬虫之旅中的一段小插曲,但这段经历让我受益匪浅。我相信,在未来,会有更多的工具和技术出现,帮助我们更好地应对各种挑战,获取我们想要的数据。




