
作为一名数据采集工作者,我深知想要从社交媒体平台上获取海量数据,绕过Cloudflare这道坚固的防火墙是必不可少的。Cloudflare的WAF(Web应用防火墙)和各种反爬虫机制,如5秒盾、Turnstile CAPTCHA等,为数据采集工作设置了重重障碍。然而,随着技术的不断发展,我们也掌握了一些行之有效的方法来突破这些限制。
Cloudflare为何如此难缠?
Cloudflare作为全球最大的CDN和网络安全公司之一,其防护能力不容小觑。它通过一系列复杂的技术手段,如IP封禁、流量分析、行为识别等,来识别并阻止恶意爬虫。其中,5秒盾和Turnstile CAPTCHA是Cloudflare常用的两种反爬虫机制。
- 5秒盾: 这是一种基于行为分析的防护机制,通过监测用户的请求频率、访问模式等,来判断是否为正常用户。一旦检测到异常行为,就会触发5秒盾,要求用户等待5秒后才能继续访问。
- Turnstile CAPTCHA: 这是一种交互式验证码,要求用户完成特定的任务,例如点击图片中的特定元素,来证明自己是人类。
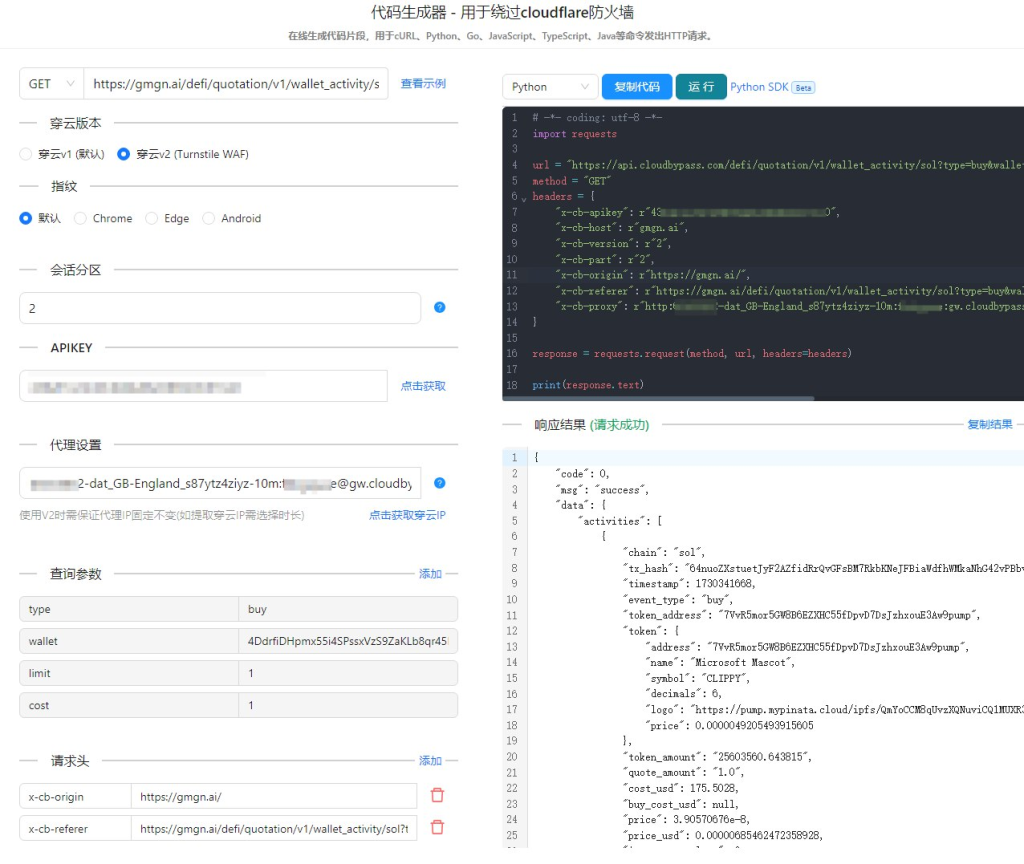
穿云API:我的破局利器
在尝试了各种传统方法后,我发现穿云API是一款非常强大的工具,它能够帮助我轻松绕过Cloudflare的各种防护机制。
穿云API的核心功能包括:
- HTTP API: 提供了简单易用的HTTP接口,方便我通过编程的方式与API进行交互。
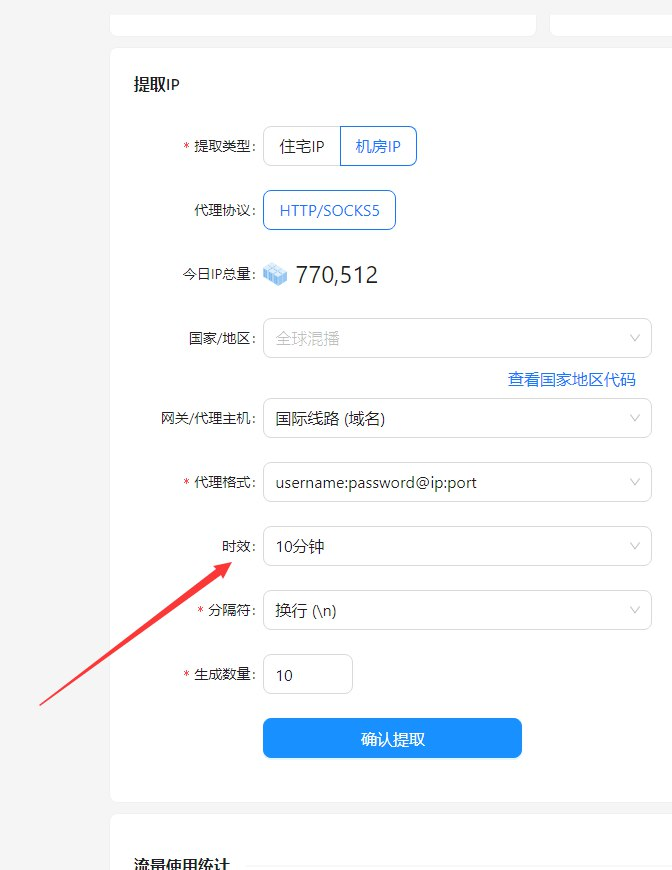
- S5动态IP代理: 内置了一站式全球高速S5动态IP代理池,能够为我提供海量的优质IP,有效避免IP被封。
- 浏览器指纹设置: 支持自定义Referer、浏览器UA、headless状态等各种浏览器指纹特征,使我的请求更加真实可靠。
- 验证码识别: 能够自动识别并解决各种类型的验证码,包括Turnstile CAPTCHA。
实战经验分享
下面,我将结合自己的实际应用经验,详细介绍如何使用穿云API来突破Cloudflare的防护,实现社交媒体数据的采集。
- 注册账号并获取API密钥: 在穿云API官网注册账号,并获取属于自己的API密钥。
- 配置请求参数: 根据API文档,设置好请求的URL、方法、头部信息等参数。
- 设置代理IP: 选择合适的代理IP,并将其添加到请求头部中。
- 处理验证码: 如果遇到验证码,调用穿云API提供的验证码识别接口,获取解题结果。
- 模拟真实用户行为: 调整Referer、UA等浏览器指纹特征,使请求更加真实。
- 处理返回结果: 解析API返回的数据,获取所需信息。
代码示例(Python):
Python
import requests
url = "https://example.com"
api_key = "your_api_key"
proxy = "http://your_proxy:port"
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/110.0.0.0 Safari/537.36",
"Referer": "https://www.google.com"
}
response = requests.get(url, headers=headers, proxies={"http": proxy})
# 处理返回结果
突破Cloudflare的那些瞬间
当我第一次成功使用穿云API绕过Cloudflare的防护,并成功获取到目标网站的数据时,那种兴奋感是难以言表的。仿佛自己解锁了一项新的技能,打开了通往数据世界的大门。
在数据采集的过程中,我们总会遇到各种各样的挑战。Cloudflare的防护无疑是其中之一。但是,通过合理利用穿云API等工具,我们可以有效地突破这些限制,获取到我们想要的数据。希望我的分享能够帮助更多的数据采集工作者,共同探索数据的海洋。




