
你是否曾为获取海量网络数据而苦恼?当爬虫面对Cloudflare这堵高墙时,你是否感到束手无策?Cloudflare作为一家全球领先的网络安全和性能公司,其反爬虫机制日益精进,给数据采集工作带来了巨大的挑战。那么,如何优化云端爬虫架构,巧妙地突破Cloudflare的重重验证,成为众多爬虫工程师亟待解决的问题。
Cloudflare的“护城河”:为何如此坚固?
Cloudflare是如何将网站保护得如此严密?它的一系列防护措施包括:
- 五秒盾: 通过延时加载,识别并阻挡非人类的访问行为。
- WAF: 能够检测并阻止常见的Web攻击,如SQL注入、跨站点脚本攻击等。
- 验证码: 要求用户完成特定的任务,以证明自己是人类。
- IP封禁: 对频繁发送请求的IP进行封禁。
- JavaScript渲染: 通过动态加载JavaScript,增加爬虫识别的难度。
这些防护措施就像一座坚固的城堡,将网站保护得固若金汤。
突破“围城”:优化云端爬虫架构的策略
面对Cloudflare的重重挑战,我们该如何优化云端爬虫架构,实现高效的数据采集呢?
- 合理设置请求频率: 过于频繁的请求很容易被Cloudflare识别为机器人。因此,我们需要合理设置爬虫的请求频率,模拟真实用户的访问行为。
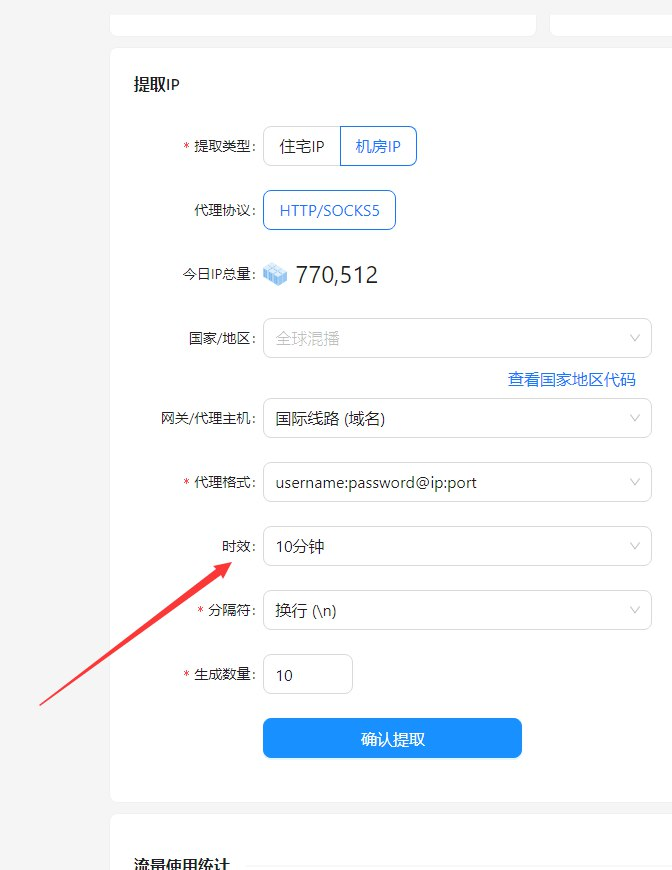
- 使用代理IP: 通过轮换使用多个代理IP,可以有效地隐藏真实IP地址,降低被封禁的风险。
- 模拟人类行为: 除了请求频率,我们还可以模拟用户的其他行为,如随机的页面停留时间、鼠标移动轨迹等,增加爬虫的真实性。
- 绕过JavaScript渲染: 可以通过无头浏览器或headless Chrome等工具来渲染页面,获取完整的页面内容。
- 验证码识别: 对于一些复杂的验证码,我们可以尝试使用验证码识别技术,但需要注意,这种方法的准确率和稳定性需要不断优化。
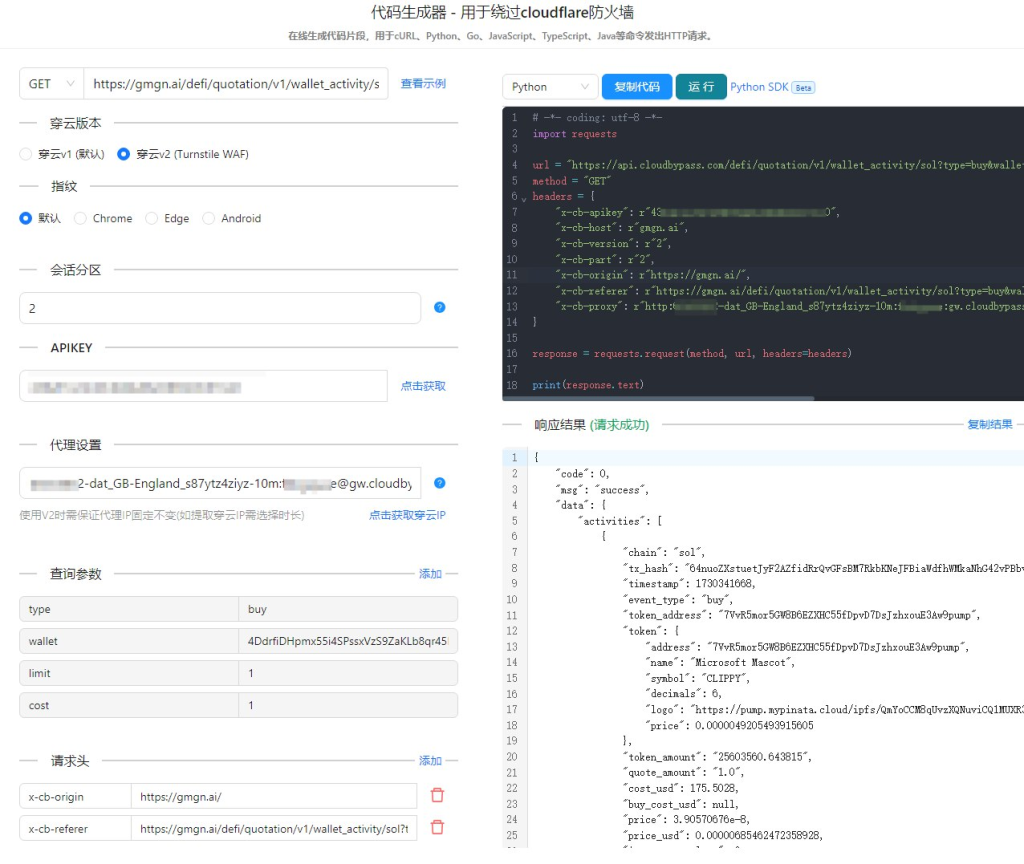
穿云API:你的破局利器
以上方法虽然有效,但实现起来往往需要大量的开发工作。有没有更便捷、高效的解决方案呢?答案是肯定的!
穿云API 是一款专门为突破Cloudflare反爬虫机制而设计的工具。它通过模拟真实浏览器行为,绕过Cloudflare的各种防护措施,帮助开发者轻松获取目标网站的数据。
穿云API 的优势在于:
- 全面的功能: 支持HTTP/HTTPS代理、SOCKS5代理、自定义头部、POST数据等功能。
- 高效稳定: 采用分布式代理池,保证服务的高可用性。
- 易于集成: 提供多种编程语言的SDK,方便开发者快速集成到自己的项目中。
案例分享:如何使用穿云API突破Cloudflare
假设我们要爬取某电商网站的商品信息,该网站使用了Cloudflare的防护。我们可以通过以下步骤来实现:
- 注册穿云API账号 并获取API密钥。
- 在代码中引入穿云API的SDK,并使用API密钥进行认证。
- 构造HTTP请求,设置目标URL、请求头等参数。
- 调用穿云API的接口发送请求,并获取响应结果。
Cloudflare的出现无疑提高了网站的安全防护水平,但同时也给数据采集带来了新的挑战。通过优化云端爬虫架构,结合穿云API等工具,我们可以有效地突破Cloudflare的验证,获取所需的数据。




