
互联网就像是一片浩瀚的海洋,而数据则是这片海洋中的宝藏。为了获取这些宝藏,我们常常会派出“爬虫”潜入其中。然而,随着网站对数据保护意识的增强,Cloudflare这样的“守门人”也越发狡猾。它们设置了重重关卡,如五秒盾、WAF、验证码等,将我们的爬虫拒之门外。那么,如何在不被发现的情况下,高效地突破Cloudflare的防线,获取我们想要的数据呢?
Cloudflare的“护城河”:层层设防
Cloudflare就像一座坚固的堡垒,它为网站提供了多重防护:
- 五秒盾: 这就像是一道闸门,只有“正常”的访客才能通过。对于频繁访问或行为异常的爬虫,它会毫不犹豫地将其拦下。
- WAF: 这是一堵“防火墙”,能够有效拦截常见的网络攻击,同时也对爬虫的请求进行严格审查。
- 验证码: 这是一道“关卡”,只有通过验证才能进入下一层。对于机器来说,破解验证码是一项极具挑战性的任务。
API:爬虫的“瑞士军刀”
面对Cloudflare的重重阻碍,我们该如何应对?答案是:API。API就像一把“瑞士军刀”,它提供了一套标准化的接口,让我们可以与各种服务进行交互。通过巧妙地利用API,我们可以绕过Cloudflare的很多限制。
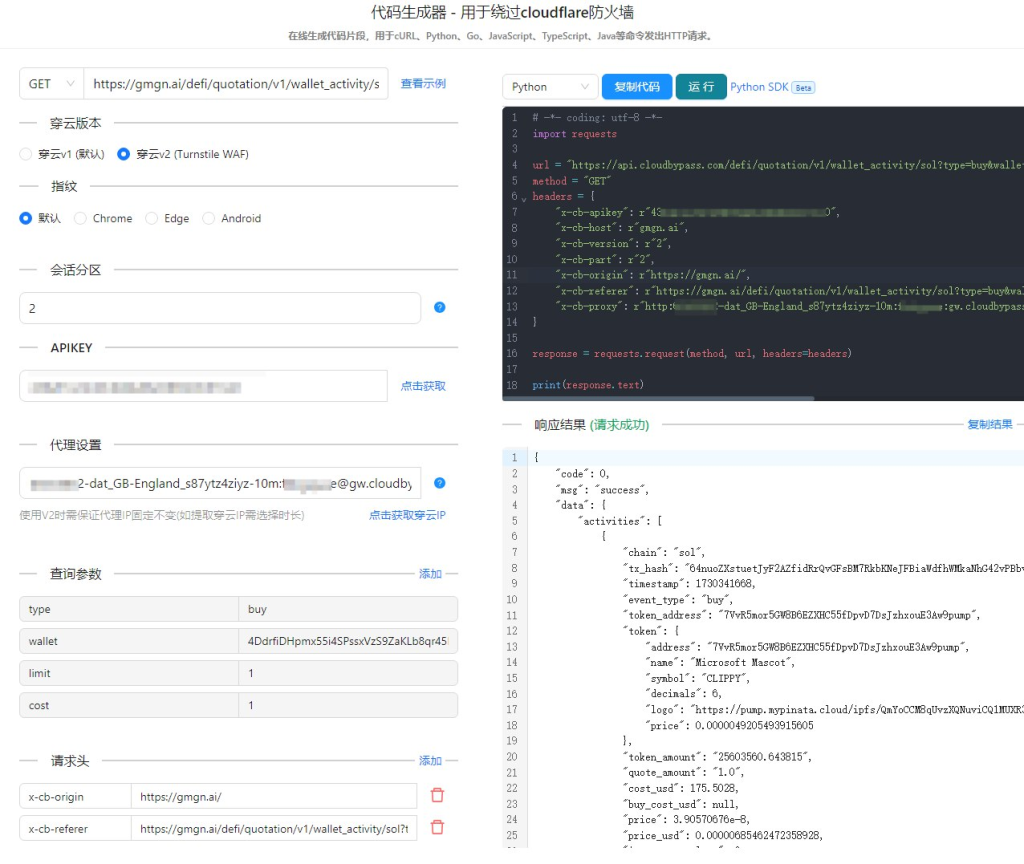
1. 穿云API:你的破局利器
穿云API是一款专门为突破Cloudflare反爬虫机制而设计的工具。它就像是一位经验丰富的“老司机”,对Cloudflare的各种防护手段了如指掌。通过穿云API,我们可以:
- 模拟真实用户行为: 穿云API可以模拟真实的浏览器环境,包括User-Agent、Cookie等,让我们的请求看起来就像是由一个真实用户发出的。
- 绕过五秒盾: 穿云API可以智能地处理五秒盾,帮助我们快速通过验证。
- 破解验证码: 穿云API集成了强大的验证码识别功能,可以自动识别并解决各种类型的验证码。
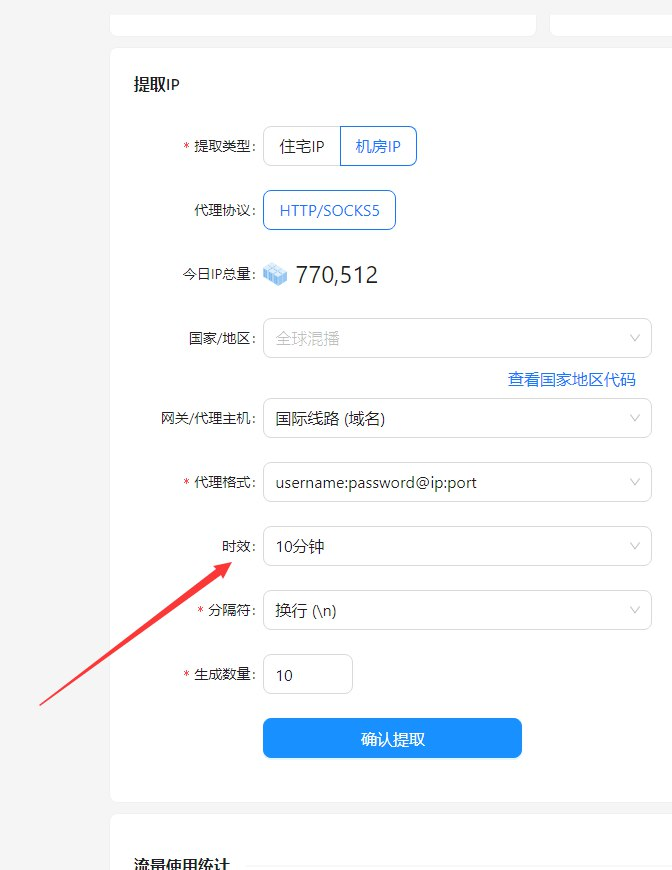
- 隐藏真实IP: 穿云API提供大量的代理IP,可以有效地隐藏我们的真实IP,避免被Cloudflare封禁。
2. 其他API的妙用
除了穿云API,我们还可以利用其他一些API来增强我们的爬虫能力:
- 搜索引擎API: 通过搜索引擎API,我们可以获取到大量的数据,而无需直接访问目标网站。
- 第三方数据提供商API: 很多第三方数据提供商提供了丰富的数据接口,我们可以通过这些接口获取到我们想要的数据。
高效爬虫开发的技巧
- 合理设置请求频率: 过于频繁的请求很容易被Cloudflare识别为爬虫,因此我们需要合理设置请求间隔。
- 多样化请求头: 通过随机生成不同的User-Agent、Referer等请求头,可以增加请求的随机性。
- 使用代理IP: 使用多个代理IP可以有效地分散风险,避免被封禁。
- 动态渲染页面: 对于JavaScript渲染的页面,我们可以使用无头浏览器来模拟浏览器的行为,获取完整的页面内容。
爬虫与反爬虫的博弈永无止境
爬虫与反爬虫的博弈就像是一场永无止境的战争。Cloudflare不断升级自己的防护措施,而我们也在不断寻找新的突破方法。通过合理利用API,我们可以更好地应对Cloudflare的挑战,获取我们想要的数据。
本文通过生动的比喻和通俗易懂的语言,深入浅出地介绍了如何通过API,尤其是穿云API,来高效地绕过Cloudflare的防护,实现数据爬取。同时,文章也强调了在爬虫开发过程中需要注意的法律和伦理问题。希望本文能为广大爬虫爱好者提供一些有价值的参考。




